Kapitel 17 Untertitel
17.1 Programme starten
library(tidyverse)
library(tidytext)
library(scales)
library(udpipe)
stringsAsFactors = FALSE17.2 Daten laden
Die englischen und deutschen Untertitel zum Film Avatar stammen aus der Datensammlung von Natalia Levshina (Levshina 2015), die slowenischen Untertitel stammen von der Webseite nachschauen.
Zuerst laden wir sechs Dateien mit Untertiteln zum Film Avatar. Hauptsächlich werden wir mit den Untertiteln in englischer, deutscher und slowenischer Sprache arbeiten.
library(tidyverse)
avatar_eng = read_lines("data/sub/Avatar_eng.txt")
avatar_deu = read_lines("data/sub/Avatar_deu.txt")
avatar_slv = read_lines("data/sub/Avatar_slv.txt")
avatar_fra = read_lines("data/sub/Avatar_fra.txt")
avatar_ita = read_lines("data/sub/Avatar_ita.txt")
avatar_tur = read_lines("data/sub/Avatar_tur.txt")head(avatar_eng); head(avatar_deu); head(avatar_slv)## [1] "1"
## [2] "00:00:39,799 --> 00:00:42,039"
## [3] "When I was lying there in the VA hospital,"
## [4] ""
## [5] "2"
## [6] "00:00:42,176 --> 00:00:45,136"## [1] "1"
## [2] "00:00:39,798 --> 00:00:42,091"
## [3] "Als ich da im Veteranen-Krankenhaus lag,"
## [4] ""
## [5] "2"
## [6] "00:00:42,176 --> 00:00:45,136"## [1] ""
## [2] "1"
## [3] "00:00:38,160 --> 00:00:40,720"
## [4] "<i>Ko sem ležal v veteranski bolnišnici</i>"
## [5] ""
## [6] "2"17.3 Datensätze vorbereiten
17.3.1 Textspalte vorbereiten
Untertitel haben ein besonderes Format. Recht einfach sind Datenmodifizierungen mit den tidyverse-Funktionen. Die Voraussetzung für ihre Verwendung ist die Umwandlung der Texte ins Tabellenformat. Dann können wir z.B. auch neue Tabellenspalten mit den Zeitangaben bilden.
a1 = avatar_eng %>%
as_tibble() %>%
mutate(row_tc = row_number()) %>%
filter(str_detect(value, "-->")) %>%
rename(timecode = value)
a2 = avatar_eng %>%
as_tibble() %>%
mutate(row_id = row_number()) %>%
filter(str_detect(value, "[a-zA-Z]")) %>%
rename(text = value) %>%
mutate(text = str_replace(text, "\\<i\\>", "")) %>%
mutate(text = str_replace(text, "\\</i\\>", "")) %>%
mutate(language = "eng")
avatar_eng = bind_cols(a1,a2) %>%
select(timecode, text) %>%
separate(timecode, into = c("start", "end"), sep = "\\-\\-\\>") %>%
rmarkdown::paged_table()
a2a = a2 %>%
mutate(sentence_id = row_number())Da die Anfangs- und Endzeit der Untertitel in den drei Sprachen nicht übereinstimmt, wollen wir lediglich die Untertiteltexte beibehalten.
b1 = avatar_deu %>%
as_tibble() %>%
mutate(row_tc = row_number()) %>%
filter(str_detect(value, "-->")) %>%
rename(timecode = value)
b2 = avatar_deu %>%
as_tibble() %>%
mutate(row_id = row_number()) %>%
filter(str_detect(value, "[a-zA-Z]")) %>%
rename(text = value) %>%
mutate(text = str_replace(text, "\\<i\\>", "")) %>%
mutate(text = str_replace(text, "\\</i\\>", "")) %>%
mutate(language = "deu")
# avatar_deu = bind_cols(a1,a2)
# select(timecode, text) %>%
# separate(timecode, into = c("start", "end"), sep = "\\-\\-\\>")
# tail(avatar_deu)
b2a = b2 %>%
mutate(sentence_id = row_number())c1 = avatar_slv %>%
as_tibble() %>%
mutate(row_tc = row_number()) %>%
filter(str_detect(value, "-->")) %>%
rename(timecode = value)
c2 = avatar_slv %>%
as_tibble() %>%
mutate(row_id = row_number()) %>%
filter(str_detect(value, "[a-zA-Z]")) %>%
rename(text = value) %>%
mutate(text = str_replace(text, "\\<i\\>", "")) %>%
mutate(text = str_replace(text, "\\</i\\>", "")) %>%
mutate(language = "slv")
# avatar_slv = bind_cols(a1,a2)
# select(timecode, text) %>%
# separate(timecode, into = c("start", "end"), sep = "\\-\\-\\>")
# tail(avatar_slv)
c2a = c2 %>%
mutate(sentence_id = row_number())avatar_fra = avatar_fra %>%
as_tibble() %>%
mutate(row_id = row_number()) %>%
filter(str_detect(value, "[a-zA-Z]")) %>%
rename(text = value) %>%
mutate(text = str_replace(text, "\\<i\\>", "")) %>%
mutate(text = str_replace(text, "\\</i\\>", "")) %>%
mutate(language = "fra") %>%
mutate(sentence_id = row_number())
avatar_ita = avatar_ita %>%
as_tibble() %>%
mutate(row_id = row_number()) %>%
filter(str_detect(value, "[a-zA-Z]")) %>%
rename(text = value) %>%
mutate(text = str_replace(text, "\\<i\\>", "")) %>%
mutate(text = str_replace(text, "\\</i\\>", "")) %>%
mutate(language = "ita") %>%
mutate(sentence_id = row_number())
avatar_tur = avatar_tur %>%
as_tibble() %>%
mutate(row_id = row_number()) %>%
filter(str_detect(value, "[a-zA-Z]")) %>%
rename(text = value) %>%
mutate(text = str_replace(text, "\\<i\\>", "")) %>%
mutate(text = str_replace(text, "\\</i\\>", "")) %>%
mutate(language = "tur") %>%
mutate(sentence_id = row_number())17.3.2 Datensätze verknüpfen
Nun verknüpfen wir die drei Datensätze zu einem einzigen.
avatar = bind_rows(a2a,b2a,c2a, avatar_fra, avatar_ita, avatar_tur)17.3.3 Merkmale hinzufügen
Mit Hilfe von quanteda-Funktionen fügen wir dem Datensatz noch weitere Kenngrößen hinzu, und zwar die Anzahl der Wortformerscheinungen oder Tokens pro Äußerung (sentlen), die Anzahl der Silben pro Äußerung (syllables), die Wortlänge (wordlen), die Anzahl der verschiedenen Wortformen (Types) und das Type-Token-Verhältnis als bekanntes Maß für lexikalische Diversität.
avatar = avatar %>%
mutate(txt = str_replace_all(text, "[:punct:]", "")) %>%
mutate(sentlen = quanteda::ntoken(txt)) %>%
mutate(syllables = nsyllable::nsyllable(txt)) %>%
mutate(types = quanteda::ntype(txt)) %>%
mutate(wordlen = syllables/sentlen) %>%
mutate(ttr = types/sentlen) %>%
select(-txt)Speichern für spätere Verwendung.
write_rds(avatar, "data/avatar.rds")
write_csv(avatar, "data/avatar.csv")avatar = read_rds("data/avatar.rds")17.3.4 Konkordanzrecherche
Ein Beispiel einer Konkordanzrecherche mit Hilfe von kwic - dem Konkordanz-Tool in quanteda:
x = quanteda::corpus(avatar, text_field = "text") %>%
quanteda::tokens()
quanteda::kwic(x, pattern = "planet") %>% as_tibble() %>%
rmarkdown::paged_table()17.3.5 Textzerlegung
Zerlegung der Untertitellinien in Wörter:
library(tidytext)
avatar_words = avatar %>%
unnest_tokens(word, text, drop = FALSE) %>%
select(-text)
avatar_words %>% rmarkdown::paged_table()17.3.6 Zerlegung und Annotation
Zuerst müssen wir für jede Sprache ein udpipe-Sprachmodell laden, um für jede der drei Untertitelversionen eine morphosyntaktische Annotation vorzunehmen.
Englisch:
library(udpipe)
destfile = "english-ewt-ud-2.5-191206.udpipe"
if(!file.exists(destfile)){
language_model <- udpipe_download_model(language = "english")
engmod <- udpipe_load_model(language_model$file_model)
} else {
file_model = destfile
engmod <- udpipe_load_model(file_model)
}x = udpipe_annotate(engmod, x = avatar$text[avatar$language == "eng"], trace = FALSE)
udeng = as.data.frame(x)Deutsch:
library(udpipe)
destfile = "german-hdt-ud-2.5-191206.udpipe"
# destfile = "german-gsd-ud-2.5-191206.udpipe"
if(!file.exists(destfile)){
language_model <- udpipe_download_model(language = "german")
deumod <- udpipe_load_model(language_model$file_model)
} else {
file_model = destfile
deumod <- udpipe_load_model(file_model)
}x = udpipe_annotate(deumod, x = avatar$text[avatar$language == "deu"], trace = F)
uddeu = as.data.frame(x)Slowenisch:
library(udpipe)
destfile = "slovenian-ssj-ud-2.5-191206.udpipe"
# destfile = "german-gsd-ud-2.5-191206.udpipe"
if(!file.exists(destfile)){
language_model <- udpipe_download_model(language = "slovenian")
slvmod <- udpipe_load_model(language_model$file_model)
} else {
file_model = destfile
slvmod <- udpipe_load_model(file_model)
}x = udpipe_annotate(slvmod, x = avatar$text[avatar$language == "slv"], trace = F)
udslv = as.data.frame(x)Französisch:
library(udpipe)
destfile = "french-gsd-ud-2.5-191206.udpipe"
if(!file.exists(destfile)){
language_model <- udpipe_download_model(language = "french-gsd")
framod <- udpipe_load_model(language_model$file_model)
} else {
file_model = destfile
framod <- udpipe_load_model(file_model)
}x = udpipe_annotate(framod, x = avatar$text[avatar$language == "fra"], trace = FALSE)
udfra = as.data.frame(x)Italienisch:
library(udpipe)
destfile = "italian-isdt-ud-2.5-191206.udpipe"
if(!file.exists(destfile)){
language_model <- udpipe_download_model(language = "italian-isdt")
itamod <- udpipe_load_model(language_model$file_model)
} else {
file_model = destfile
itamod <- udpipe_load_model(file_model)
}x = udpipe_annotate(itamod, x = avatar$text[avatar$language == "ita"], trace = FALSE)
udita = as.data.frame(x)Türkisch:
library(udpipe)
destfile = "turkish-imst-ud-2.5-191206.udpipe"
if(!file.exists(destfile)){
language_model <- udpipe_download_model(language = "turkish-imst")
turmod <- udpipe_load_model(language_model$file_model)
} else {
file_model = destfile
turmod <- udpipe_load_model(file_model)
}x = udpipe_annotate(turmod, x = avatar$text[avatar$language == "tur"], trace = FALSE)
udtur = as.data.frame(x)Anpassung der Tabellenspalte “token_id” als numeric().
udfra = udfra %>%
separate(token_id,
into = c("token_id", "token_id2"), sep = "-") %>%
mutate(token_id = as.numeric(token_id)) %>%
select(-token_id2)
udita = udita %>%
separate(token_id,
into = c("token_id", "token_id2"), sep = "-") %>%
mutate(token_id = as.numeric(token_id)) %>%
select(-token_id2)
udtur = udtur %>%
separate(token_id,
into = c("token_id", "token_id2"), sep = "-") %>%
mutate(token_id = as.numeric(token_id)) %>%
select(-token_id2)Die Datensätze wollen wir für anderweitige Verwendungen speichern, und zwar sowohl im conllu-Format als auch im csv-Format. In beiden Fällen erhalten wir Textdateien.
write.table(as_conllu(udeng), file = "data/Avatar_ud_eng.conllu",
sep = "\t", quote = F, row.names = F)
write.table(as_conllu(uddeu), file = "data/Avatar_ud_deu.conllu",
sep = "\t", quote = F, row.names = F)
write.table(as_conllu(udslv), file = "data/Avatar_ud_slv.conllu",
sep = "\t", quote = F, row.names = F)
write.table(as_conllu(udfra), file = "data/Avatar_ud_fra.conllu",
sep = "\t", quote = F, row.names = F)
write.table(as_conllu(udita), file = "data/Avatar_ud_ita.conllu",
sep = "\t", quote = F, row.names = F)
write.table(as_conllu(udtur), file = "data/Avatar_ud_tur.conllu",
sep = "\t", quote = F, row.names = F)write_csv(udeng, "data/Avatar_ud_eng.csv")
write_csv(uddeu, "data/Avatar_ud_deu.csv")
write_csv(udslv, "data/Avatar_ud_slv.csv")
write_csv(udfra, "data/Avatar_ud_fra.csv")
write_csv(udita, "data/Avatar_ud_ita.csv")
write_csv(udtur, "data/Avatar_ud_tur.csv")udeng = read_csv("data/Avatar_ud_eng.csv")
uddeu = read_csv("data/Avatar_ud_deu.csv")
udslv = read_csv("data/Avatar_ud_slv.csv")
udfra = read_csv("data/Avatar_ud_fra.csv")
udita = read_csv("data/Avatar_ud_ita.csv")
udtur = read_csv("data/Avatar_ud_tur.csv")Den drei annotierten Datensätzen wollen wir noch einige weitere Merkmale hinzufügen (und zwar mit den mutate()-Befehlen, in denen auch einfache quanteda-Funktionen verwendet werden). Außerdem soll die komplexe Tabellenspalte feats (features) in einzelne Spalten aufgeteilt werden (und zwar mit der cbind_morphological()-Funktion von udpipe).
Da wir dies mit allen drei Datensätzen anstellen wollen, bilden wir eine Funktion dazu, die als Input eine Tabelle (tbl) verlangt, in denen die Spalten “word, token, feats, sentence” zur Verfügung stehen:
tokenize_annotate = function(tbl){
tbl %>%
unnest_tokens(word, token, drop = F) %>%
cbind_morphological(term = "feats",
which = c("PronType","NumType","Poss","Reflex",
"Foreign","Abbr","Typo",
"Gender","Animacy","NounClass",
"Case","Number","Definite","Degree",
"VerbForm","Person","Tense","Mood",
"Aspect","Voice","Evident",
"Polarity","Polite","Clusivity")) %>%
mutate(txt = str_replace_all(sentence, "[:punct:]", "")) %>%
mutate(sentlen = quanteda::ntoken(txt)) %>%
mutate(syllables = nsyllable::nsyllable(txt)) %>%
mutate(types = quanteda::ntype(txt)) %>%
mutate(wordlen = syllables/sentlen) %>%
mutate(ttr = types/sentlen) %>%
select(-txt, -feats)
}Die für die Verwendung der Funktion entsprechenden Tabellen sind die zuvor gebildeten Tabellen “udeng”, “uddeu” und “udslv”. Nach der Anreicherung der Datensätze verknüpfen wir sie zu einem einzigen.
avatar_eng_udpiped <- udeng %>%
tokenize_annotate() %>% mutate(language = "eng")
avatar_deu_udpiped <- uddeu %>%
tokenize_annotate() %>% mutate(language = "deu")
avatar_slv_udpiped <- udslv %>%
tokenize_annotate() %>% mutate(language = "slv")
avatar_fra_udpiped <- udfra %>%
tokenize_annotate() %>% mutate(language = "fra")
avatar_ita_udpiped <- udita %>%
tokenize_annotate() %>% mutate(language = "ita")
avatar_tur_udpiped <- udtur %>%
tokenize_annotate() %>% mutate(language = "tur")
avatar_words_udpiped = bind_rows(avatar_eng_udpiped,
avatar_deu_udpiped,
avatar_slv_udpiped,
avatar_fra_udpiped,
avatar_ita_udpiped,
avatar_tur_udpiped)
avatar_words_udpiped %>% rmarkdown::paged_table()Für spätere Verwendungen speichern wir den Datensatz in zwei verschiedenen Formaten.
write_rds(avatar_words_udpiped, "data/avatar_words_udpiped.rds")
write_csv(avatar_words_udpiped, "data/avatar_words_udpiped.csv")avatar_words_udpiped = read_rds("data/avatar_words_udpiped.rds")17.4 Morphologie der Untertitel
Um einzelne Wörter und ihre Funktionen im Text aufzuspüren, brauchen wir nur die filter()- und die select()-Funktion einzugeben. Beispielsweise das Lemma “brother” in den englischen Untertiteln:
avatar_words_udpiped %>%
filter(lemma == "brother") %>%
select(sentence, token, lemma, upos, dep_rel) %>%
rmarkdown::paged_table()Dasselbe mit dem deutschen “Bruder” und dem slowenischen “brat”:
avatar_words_udpiped %>%
filter(lemma == "Bruder") %>%
select(sentence, token, lemma, upos, dep_rel) %>%
rmarkdown::paged_table()avatar_words_udpiped %>%
filter(lemma == "brat") %>%
select(sentence, token, lemma, upos, dep_rel) %>%
rmarkdown::paged_table()Das Lemma “brother” bzw. scheint in den englischen Untertiteln ein wenig häufiger vorzukommen als die deutsche bzw. slowenische Entsprechung “Bruder” bzw. “brat”.
17.4.1 XRay Brother
An welchen Stellen kommt das Wort in den Untertiteln vor?
quanteda.textplots::textplot_xray(
quanteda::kwic(avatar %>% pull(text),
pattern = c("brother","Bruder","brat")),
scale = "relative")
Um die Stellen aus drei Texten besser vergleichen zu können, müssen wir drei xray-Diagramme erstellen und sie mit Hilfe von patchwork zusammenkleben.
p1 = quanteda.textplots::textplot_xray(
quanteda::kwic(avatar %>% filter(language == "eng") %>% pull(text),
pattern = "brother"), scale = "relative")
p2 = quanteda.textplots::textplot_xray(
quanteda::kwic(avatar %>% filter(language == "deu") %>% pull(text),
pattern = "Bruder"), scale = "relative")
p3 = quanteda.textplots::textplot_xray(
quanteda::kwic(avatar %>% filter(language == "slv") %>% pull(text),
pattern = "brat"), scale = "relative")
library(patchwork)
p1|p2|p3
17.4.2 Substantive im Plural
Als nächstes wollen wir alle als Substantive (Noun) identifizierte Einheiten herausfinden, die im Plural auftreten.
#Find all plural nouns (tokens)
avatar_words_udpiped %>%
filter(language == "eng" &
upos == "NOUN" &
morph_number == "Plur") %>%
select(sentence, token, lemma, upos, morph_number) %>%
rmarkdown::paged_table()avatar_words_udpiped %>%
filter(language == "deu" &
upos == "NOUN" &
morph_number == "Plur") %>%
select(sentence, token, lemma, upos, morph_number) %>%
rmarkdown::paged_table()avatar_words_udpiped %>%
filter(language == "slv" &
upos == "NOUN" &
morph_number == "Plur") %>%
select(sentence, token, lemma, upos, morph_number) %>%
rmarkdown::paged_table()avatar_words_udpiped %>%
dplyr::select(language, token, lemma, upos, morph_number) %>%
group_by(language) %>%
filter(upos == "NOUN") %>%
count(morph_number) %>%
pivot_wider(names_from = language, values_from = n) %>%
# mutate(across(everything(), ~ replace_na(.x, 0))) %>%
mutate_if(is.numeric, ~ replace_na(.x, 0)) %>%
mutate(morph_number =
str_replace(morph_number, "0", "Unknown")) %>%
mutate(morph_number =
fct_relevel(
morph_number, levels =
c("Sing","Plur","Dual","Unknown"))) %>%
arrange(morph_number) %>%
rmarkdown::paged_table()17.4.3 Adjektive im Komparativ
In unserer nächsten Recherche wollen wir Komparativformen von Adjektiven ausfindig machen und ihre Stelle im Untertitel.
Zuerst zählen wir die Wortarten (upos). Hier fällt auf, dass der Anteil einiger Wortarten in den slowenischen Untertiteln größer ist als in den anderen beiden Sprachen (z.B. Verben, Substantive), in anderen Fällen jedoch kleiner (z.B. Pronomen, die ja im Slowenischen nicht obligatorisch auftreten müssen).
# Frequencies of parts of speech
avatar_words_udpiped %>%
group_by(language) %>%
count(upos, sort = TRUE) %>%
mutate(pct = round(100*n/sum(n),2)) %>%
pivot_wider(names_from = language, values_from = c(n, pct)) %>%
arrange(upos) %>%
rmarkdown::paged_table()In den englischen Untertiteln wurden 17 Komparativformen identifiziert, in den deutschen 20 und in den slownischen 4. Der Anteil der Komparativformen ist also in den englischen und deutschen Untertiteln größer als in den slowenischen.
Ähnlich verhält es sich mit den Superlativformen: deutsch (35 = 6%), englisch (14 = 2,77%), slowenisch (6 = 1,65)
avatar_words_udpiped %>%
group_by(language) %>%
filter(language == "eng" |
language == "deu" | language == "slv") %>%
filter(upos == "ADJ") %>%
count(morph_degree, sort = TRUE) %>%
mutate(pct = round(100*n/sum(n),2)) %>%
pivot_wider(names_from = language, values_from = c(n, pct)) %>%
# mutate(across(everything(), ~ replace_na(.x, 0))) %>%
mutate_if(is.numeric, ~ replace_na(.x, 0)) %>%
mutate(morph_degree =
str_replace(morph_degree, "0", "Unknown")) %>%
mutate(morph_degree =
fct_relevel(
morph_degree, levels =
c("Pos","Cmp","Sup","Abs","Unkown"))) %>%
arrange(morph_degree) %>%
rmarkdown::paged_table()Anmerkung: Die Klassifzierung für die deutsche Sprache (Variante: “german-gsd”) enthält diese Kategorie nicht. Wir haben daher die “german-hdt”-Variante gewählt.
17.5 Syntax: Dependenz
Programme wie udpipe oder spacyr sind auch in der Lage, syntaktische Dependenzrelationen gemäß der Stanforder sprachübergreifenden Typologie zu identifizieren und als Annotation auszugeben. Typologische Grundlage für die Annotation: Universal Stanford Dependencies: A cross-linguistic typology (de Marneffe et al. 2014).
knitr::include_graphics("pictures/Screenshot 2021-08-27 at 12-14-22 Universal Dependency Relations.png")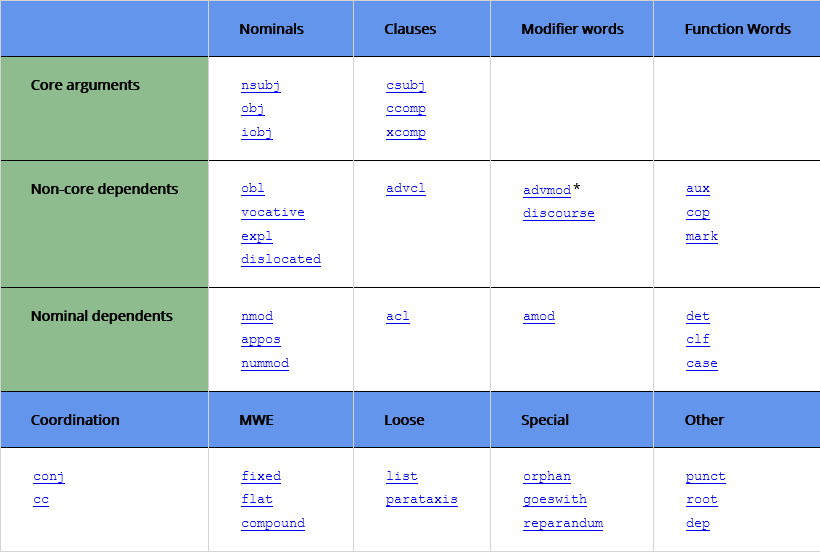
Mehr über das Datenformat: CoNLL-U Format
Frequenzwerte der syntaktischen Abhängigkeitsrelationen in den Avatar-Untertiteln (englisch, deutsch, slowenisch):
avatar_words_udpiped %>%
group_by(language) %>%
filter(language == "eng" |
language == "deu" | language == "slv") %>%
count(dep_rel, sort = TRUE) %>%
mutate(pct = round(100*n/sum(n),2)) %>%
pivot_wider(names_from = language, values_from = c(n, pct)) %>%
# mutate(across(everything(), ~ replace_na(.x, 0))) %>%
mutate_if(is.numeric, ~ replace_na(.x, 0)) %>%
mutate(dep_rel =
str_replace(dep_rel, "0", "Unknown")) %>%
rmarkdown::paged_table()Gemäß udpipe erscheinen in den englischen und deutschen Untertiteln die Dependenzrelationen root, nsubj, advmod, det, obj am häufigsten. In den slowenischen Untertiteln haben die Relationen root, advmod, obj, case, nsubj die größten Frequenzwerte.
Die Dependenzrelation root gibt uns Auskunft darüber, ob eine Wortfolge als Satz identifiziert wurde. Sie wird gewöhnlich mit Hilfe des (finiten) Verbs im Satz bestimmt. In elliptischen Sätzen wird eine der vorkommenden Wortformen mit root assoziiert.
In der Tabelle ist (unter root) zu sehen, dass in den englischen Untertiteln 2026 satzwertige Einheiten identifiziert wurden, in den deutschen 2366 und in den slowenischen 1807.
In der Tabelle zeigen die Prozentzahlen beispielsweise einen bemerkenswerten Unterschied in der Häufigkeit der Dependenzrelation nsubj, d.h. die Anzahl der identifizierten Subjekte. In den slowenischen Untertiteln liegt der Anteil deutlich unter dem in den englischen und deutschen. Das hängt damit zusammen, dass Slowenisch eine Pro-drop-Sprache ist, dass also unbetonte Personalpronomen (in Subjekt-Funktion) nicht sprachlich realisiert zu sein brauchen. Besonder deutlich wird dies, wenn wir einen Beispielsatz aus allen drei Texten visualisieren.
Mit Hilfe der folgenden Funktion können wir die Dependenzrelationen im Satz visualisieren. Wir geben der Funktion den Namen plot_annotation().
library(igraph)
library(ggraph)
library(ggplot2)
plot_annotation <- function(x, size = 3){
stopifnot(is.data.frame(x) & all(c("sentence_id", "token_id", "head_token_id", "dep_rel", "token_id", "token", "lemma", "upos", "xpos", "feats") %in% colnames(x)))
x <- x[!is.na(x$head_token_id), ]
x <- x[x$sentence_id %in% min(x$sentence_id), ]
edges <- x[x$head_token_id != 0, c("token_id", "head_token_id", "dep_rel")]
edges$label <- edges$dep_rel
g <- graph_from_data_frame(edges,
vertices = x[, c("token_id", "token", "lemma", "upos", "xpos", "feats")],
directed = TRUE)
windowsFonts("Arial Narrow" = windowsFont("Arial"))
ggraph(g, layout = "linear") +
geom_edge_arc(ggplot2::aes(label = dep_rel, vjust = -0.20),
arrow = grid::arrow(length = unit(4, 'mm'), ends = "last", type = "closed"),
end_cap = ggraph::label_rect("wordswordswords"),
label_colour = "red", check_overlap = TRUE, label_size = size) +
geom_node_label(ggplot2::aes(label = token), col = "darkgreen", size = size, fontface = "bold") +
geom_node_text(ggplot2::aes(label = upos), nudge_y = -0.35, size = size) +
theme_graph(base_family = "Arial Narrow") +
labs(title = "udpipe output", subtitle = "tokenisation, parts of speech tagging & dependency relations")
}Hier ist ein Beispiel eines Avatar-Untertitels in drei Sprachen. Wegen der deutschen bzw. slowenischen Sonderzeichen wandeln wir den Text mit Hilfe der Funktion enc2utf8() ins erforderliche UTF8-Format um.
# English
mytext = udpipe("I started having these dreams of flying", "english")
x1 = plot_annotation(mytext, size = 3)
# German
mytext = "Ich träumte auf einmal vom Fliegen" %>% enc2utf8()
x = udpipe(mytext, "german")
x2 = plot_annotation(x, size = 3)
# Slovenian
mytext = "Začel sem sanjati o letenju" %>% enc2utf8()
x = udpipe(mytext, "slovenian")
x3 = plot_annotation(x, size = 3)Englischer Satz:
PRON: Personalpronomen mit Subjekt-Funktion (nsubj)
NOUN, VERB: Substantiv, Verb
AUX: das Hilfs- oder Auxiliarverb
xcomp: hier eine Relation zwischen zwei Verben, die gemeinsam das Prädikat des Satzes bilden
DET: Determiner (Determinans), Begleiter eines Substantivs (meist handelt es sich um einen Artikel)
obj: Objektfunktion (hier ist “these dreams” das Objekt des Verbs “have”)
SCONJ: subordinierende Konjunktion (aber hier wäre “prep” für Präposition angebracht)
acl: gewöhnlich bezogen auf einen finiten oder infiniten Satz, der eine Nominalphrase modifiziert (im Kontrast zu advcl, die ein Prädikat modifizieren)
mark: ein Marker, der eine untergerodnete Phrase / Satz kennzeichnet.
x1
Deutscher Satz:
PRON: Personalpronomen mit Subjekt-Funktion (nsubj)
NOUN, VERB, ADP, ADV: Substantiv, Verb, Adposition (hier: Präposition), Adverb
DET: Determiner (Determinans), Begleiter eines Substantivs (meist handelt es sich um einen Artikel)
obl: eine Art von Adjunkt, in der Valenzgrammatik gewöhnlich als Präpositionalobjekt klassifizert (hier ist “vom Fliegen” das Objekt des Verbs “have”)
case: Element, das den Kasus einer Phrase regiert (z.B. “von” regiert den Dativ der Nominalphrase “dem Fliegen”)
advmod: Element, das das Prädikat modifizert (Adverbialphrase).
x2
Slowenischer Satz:
Das Personalpronomen mit Subjekt-Funktion fehlt, daher auch keine Subjekt-Relation (nsubj) angezeigt.
In slowenischen Nominalphrasen sind Begleiter (DET) nicht obligatorisch bzw. default (slow. “privzeto”) wie etwa im Englischen oder Deutschen.
NOUN, VERB, ADP: Substantiv, Verb, Adposition (hier: Präposition)
AUX: das Hilfs- oder Auxiliarverb
DET: Determiner (Determinans), Begleiter eines Substantivs (meist handelt es sich um einen Artikel)
xcomp: hier eine Relation zwischen zwei Verben, die gemeinsam das Prädikat des Satzes bilden (“začel sanjati”)
obl: eine Art von Adjunkt, in der Valenzgrammatik gewöhnlich als Präpositionalobjekt klassifizert (hier ist “o letenju” das Objekt des Verbs “sanjati”)
case: Element, das den Kasus einer Phrase regiert (z.B. die Präposition “o” regiert den Dativ der Nominalphrase “letenju”).
x3
Aus den drei Diagrammen ist ersichtlich, dass die Subjekt-Relation (nsubj) im englischen und deutschen Satz mittels eines Personalpronomens (PRON) realisiert wird, während das Subjekt im slowenischen Satz mittels der finiten Verbform, einem Hilfs- oder Auxiliarverbs (AUX), (mit)ausgedrückt wird, also im Hilfsverb “versteckt” auftritt. Im slowenischen Satz ist PRON syntaktisch nicht notwendig, im englischen und deutschen schon. Das wirkt sich natürlich auf die Frequenzwerte bzw. den Pronzenanteil aus (s. Tabelle).
Die Diagramme zeigen strukturelle Ähnlichkeiten und Unterschiede zwischen den Sprachversionen:
sowohl im englischen Untertitel als auch in der slowenischen Version wird eine xcomp-Relation angegeben, d.h. dass das Satzprädikat mit Hilfe von zwei Verben konstituiert wird (“started having” vs. “začel sanjati”). Die Verben “started” bzw. “začeti” modifizeren das Hauptverb “have” bzw. “sanjati” temporal. Im deutschen Untertitel wird stattdessen ein einfaches Prädikat (“träumte”) verwendet, dass durch eine Adverbialphrase (“auf einmal”) temporal modifiziert wird.
das englische Substantiv “dream” wird im deutschen und slowenischen Untertitel im Satzprädikat ausgedrückt (“träumte”, “sanjati”)
der englische Subordinationsmarker “of”, der sich sowohl auf Nominalphrasen als auch auf Sätze beziehen kann, wird im deutschen und slowenischen Untertitel mit einer spezifischeren Wortklasse ausgedrückt, nämlich mit einer Präposition (ADP, Adposition).
17.5.1 Aktiv und Passiv
Wie groß ist der Anteil aktivischer und passivischer Sätze in den drei Sprachversionen? Dies können wir mit Hilfe der nsubj-Relation erfahren. In den englischen und deutschen Untertiteln wurden je 34 passivische Subjekte identifizert, in den slowenischen keiner.
avatar_words_udpiped %>%
group_by(language) %>%
filter(language == "eng" |
language == "deu" | language == "slv") %>%
filter(str_detect(dep_rel, "nsubj")) %>%
count(dep_rel, sort = TRUE) %>%
mutate(pct = round(100*n/sum(n),2)) %>%
pivot_wider(names_from = language, values_from = c(n, pct)) %>%
# mutate(across(everything(), ~ replace_na(.x, 0))) %>%
mutate_if(is.numeric, ~ replace_na(.x, 0)) %>%
mutate(dep_rel =
str_replace(dep_rel, "0", "Unknown")) %>%
rmarkdown::paged_table()Schauen wir uns ein paar dieser Untertitel in allen drei Sprachen an:
avatar_words_udpiped %>%
group_by(language) %>%
filter(language == "eng") %>%
filter(str_detect(dep_rel, "nsubj:pass")) %>%
ungroup() %>%
select(sentence, sentence_id) %>%
distinct() %>%
head(5) %>% rmarkdown::paged_table()- Wir wählen einen englischen Untertitel als Beispiel, und zwar: “And the concept is that ervery driver is matched to his own avatar*”.
- Deutsche Version: “Die Idee ist, dass jeder Operator auf seinen eigenen Avatar abgestimmt wird”.
- Slowenische Version: “Vsak upravljavec dobi svojega avatarja”.
avatar %>%
filter(language == "deu") %>%
filter(str_detect(text, "jeder Operator auf") | str_detect(text, "Avatar abgestimmt")) %>%
select(text) %>% rmarkdown::paged_table()avatar %>%
filter(language == "slv") %>%
filter(str_detect(text, "dobi svojega avatarja")) %>%
select(text) %>% rmarkdown::paged_table()Wiederum visualisieren wir die drei Sprachversionen.
# English
mytext = udpipe("And the concept is that ervery driver is matched to his own avatar", "english")
x1 = plot_annotation(mytext, size = 3)
# German
mytext = "Die Idee ist, dass jeder Operator auf seinen eigenen Avatar abgestimmt wird" %>% enc2utf8()
x = udpipe(mytext, "german")
x2 = plot_annotation(x, size = 3)
# Slovenian
mytext = "Vsak upravljavec dobi svojega avatarja" %>% enc2utf8()
x = udpipe(mytext, "slovenian")
x3 = plot_annotation(x, size = 3)x1
x2
x3
Die slowenische Version ist syntaktisch am einfachsten, denn sie besteht lediglich aus einem Hauptsatz, im englischen und deutschen Untertitel dagegen aus Haupt- und Nebensatz, wobei letztere die hauptsächliche Information trägt (die auch im slowenischen Hauptsatz zu Tage tritt). Der Hauptsatz im englischen und deutschen Untertitel kann kommunikativ betrachtet als Vorreiter oder Vorschaltung eingeordnet werden, also als Ausdruck, der vor allem zur Orientierung oder Einordnung eines Gedankens (der im Nebensatz ausgedrückt wird) in ein Gedankenschema oder Frame dient.
Die passivische Relation, die im englischen und deutschen Untertitel mittels passivischer Verbformen realisiert wird, wird im slowenischen Untertitel mit dem Verb “dobiti” zum Ausdruck gebracht (deutsch: “bekommen”, englisch: “get”). Das Subjekt des slowenischen Verb “dobiti” (hier: “vsak upravljalec”) ist semantisch gesehen ein Benefaktiv oder Nutznießer (benefaktive Relation), also ein Rezipient, für den eine Handlung vorteilhaft oder nutzbringend ist. Entsprechendes gilt auch für das deutsche bekommen-Passiv (z.B. “jeder Operator bekommt einen Avatar”.
Die Ausdrucksweise im slowenischen Untertitel ist im Vergleich zu den anderen Sprachversionen semantisch ungenau, denn es bleibt dem Leser überlassen, ob er die im Film realisierte symbiotische Verbindung zwischen Reiter und Tier nachvollziehen kann. Die Ausdrucksweise im englischen und deutschen Untertitel ist dagegen spezifischer, d.h. es handelt sich um eher eine technische (fachbezogene) Ausdrucksweise (engl. “matching”, deutsch “Abstimmung”).
Da es sich in diesem Fall um einen Vorgang oder Prozess handelt, gibt es keinen menschlichen Verursacher der Abstimmung, denn sowohl der Operator (driver, upravljalec) sind so wie das gerittene Tier lediglich Reagentien im Prozess. Das ist in allen drei Sprachversionen deckungsgleich.
In allen drei Sprachversionen wird wird der (menschliche) Benefaktiv (d.h. das syntaktische Subjekt) als Ausgangspunkt einer neuen oder wichtigen Information verwendet. Die neue Information “seinen eigenen Avatar” wird ins Rampenlicht gerückt, also zum Rhema des Satzes gemacht. Die typische Verteilung Thema vor Rhema wird hiermit in allen drei Sprachversionen gewahrt. Außerdem wird damit auch die häufigere Reihenfolge Subjekt vor Objekt eingehalten. Im slowenischen Satz handelt es sich um ein direktes Objekt (Akkusativobjekt), im englischen und deutschen dagegen um ein Präpositionalobjekt (“match to …”, “abstimmen auf …”).
17.5.2 Substantive und Pronomen als Satzglieder
Nun lenken wir unsere Sichtweise auf die Wortklassen Substantiv (NOUN) und Pronomen (PRON) in Subjekt- oder Objekt-Funktion.
avatar_words_udpiped %>%
group_by(language) %>%
filter(upos == "NOUN" | upos == "PRON") %>%
filter(str_detect(dep_rel, "nsubj|obj|obl")) %>%
count(upos, dep_rel) %>%
mutate(pct = round(100*n/sum(n),2)) %>%
pivot_wider(names_from = language, values_from = c(n, pct)) %>%
# mutate(across(everything(), ~ replace_na(.x, 0))) %>%
mutate_if(is.numeric, ~ replace_na(.x, 0)) %>%
arrange(upos) %>%
rmarkdown::paged_table()Ein erster Blick auf die Tabelle zeigt uns mehrere Unterschiede: - Pronomen erscheinen in den englischen und deutschen Untertiteln häufiger in Subjekt-Funktion als Substantive. In den slowenischen Untertiteln ist es umgekehrt, was wahrscheinlich damit zusammenhängt, dass Slowenisch eine Pro-Drop-Sprache ist (s.o.). - In Objekt-Funktion scheint das Verhältnis zwischen den beiden Wortklassen (NOUN, PRON) ausgewogener zu sein. - Das indirekte Objekt (iobj), dass sich, semantisch betrachtet, oft auf einen Adressaten oder Rezipienten bezieht, wird vorzugsweise mit einem Pronomen ausgedrückt, selten oder gar nicht mit einem Substantiv. - Für einige Satzglied-Funktionen liegen keine Zahlen vor. Das kann daran liegen, dass diese Funktionen in der verwendeten Grammatik einer der ausgewählten Sprachen nicht unterschieden wird.
Für genauere Feststellungen empfiehlt es sich, nur jeweils zwei Satzgliedfunktionen miteinander zu vergleichen.
17.5.3 Subjekt nominal / pronominal
Wie viele Subjekte im Aktiv oder Passiv werden mit Hilfe von Substantiven oder Personalpronomen ausgedrückt?
avatar_words_udpiped %>%
group_by(language) %>%
filter(language == "eng" |
language == "deu" | language == "slv") %>%
filter(upos == "NOUN" | upos == "PRON") %>%
filter(str_detect(dep_rel, "nsubj")) %>%
count(upos, dep_rel) %>%
mutate(pct = round(100*n/sum(n),2)) %>%
pivot_wider(names_from = language, values_from = c(n, pct)) %>%
# mutate(across(everything(), ~ replace_na(.x, 0))) %>%
mutate_if(is.numeric, ~ replace_na(.x, 0)) %>%
arrange(upos) %>%
rmarkdown::paged_table()Treten Pronomen genau so häufig als Passiv-Subjekte auf wie Substantive? Die obige Tabelle scheint für die englischen und deutschen Untertitel das Gegenteil zu zeigen. Machen für doch für diese beiden Sprachversionen je einen Chi-Quadrat-Test!
pivot_by_nsubj <- function(tbl) {
tbl %>%
filter(upos == "NOUN" | upos == "PRON") %>%
filter(str_detect(dep_rel, "nsubj")) %>%
count(upos, dep_rel) %>%
group_by(upos) %>%
mutate(pct = round(100*n/sum(n),2)) %>%
pivot_wider(names_from = upos, values_from = c(n, pct)) %>%
mutate_if(is.numeric, ~ replace_na(.x, 0))
# mutate(across(everything(), ~ replace_na(.x, 0)))
}
x = avatar_words_udpiped %>%
filter(language == "eng") %>%
pivot_by_nsubj()
x %>% rmarkdown::paged_table()In der letzten Tabelle fällt auf, dass der Anteil der Pronomen (pct_PRON) in der nsubj:pass-Funktion größer ist als der der Substantive (pct_NOUN). Ist dieser Unterschied zufällig (aufgrund der Stichprobenauswahl entstanden) oder können wir ihn auf die Grundgesamtheit (auf umgangssprachliche Dialoge in der englischen Sprache) verallgemeinern? Eine Antwort darauf soll uns der Chi-Quadrat-Test geben.
Für den Chi-Quadrat-Test benötigen wir lediglich die beiden Spalten mit den absoluten Zahlenwerten (also die zweite und dritte). In Base-R kann man dies sehr ökonomisch mit einer Bedingung in eckigen Klammern [] erreichen, mit der tidyverse-Funktion select() zwar transparenter und in Tabellenform, dafür muss man jedoch etwas mehr schreiben.
# Base-R
chisq.test(x[,c(2:3)])##
## Pearson's Chi-squared test with Yates' continuity correction
##
## data: x[, c(2:3)]
## X-squared = 2.2472, df = 1, p-value = 0.1339# tidyverse
x %>% select(n_NOUN, n_PRON) %>% chisq.test() %>% tidy()## # A tibble: 1 x 4
## statistic p.value parameter method
## <dbl> <dbl> <int> <chr>
## 1 2.25 0.134 1 Pearson's Chi-squared test with Yates' continuity~Der Chi-Quadrat-Test bestätigt mit dem p-Wert (0,1339) die Null-Hypothese, d.h. das es zwischen Pronomen und Substantiven als Subjekte in den englischen Untertiteln keinen statistisch signifikanten Unterschied gibt und dass der prozentuelle Unterschied aufgrund unserer Stichprobenauswahl entstanden ist (also zufällig).
Dasselbe können wir mit den deutschen Pronomen und Substantiven in Subjekt-Funktion machen. In diesem Fall ist der prozentuelle Unterschied zwischen Substantiven und Pronomen als aktivische oder passivische Subjekte größer zu sein als in der englischen Stichprobe.
x = avatar_words_udpiped %>%
filter(language == "deu") %>%
pivot_by_nsubj()
x %>% rmarkdown::paged_table()In den deutschen Untertiteln können wir mit dem Chi-Quadrat-Test einen statistisch signifikanten Unterschied zwischen Pronomen und Substantiven nachweisen (p < 0,05): Pronomen scheinen in Subjekt-Funktion seltener in Passivsätzen verwendet worden zu sein als Substantive. Möglicherweise gilt dies auch für die Grundgesamtheit in deutsche Sprache (hier vor allem für umgangssprachliche Dialoge). Anders ausgedrückt: wir haben eine (nicht zufällige) Tendenz nachgewiesen, dass das Subjekt in den deutschen Passivsätzen häufiger mit Substantiven, also autosemantischen Ausdrücken realisiert wurde.
# Base-R
chisq.test(x[,c(2:3)]) %>% tidy()## # A tibble: 1 x 4
## statistic p.value parameter method
## <dbl> <dbl> <int> <chr>
## 1 14.4 0.000149 1 Pearson's Chi-squared test with Yates' continuit~Wir können uns die entsprechenden Belege mit Passivsubjekten auch anschauen. Aus der Tabelle ist auch ersichtlich, dass die grammatische Analyse des Programms auch einige Fehler enthält (z.B. “Avatar” in “(auf) seinen eigenen Avatar abgestimmt wird” ist Bestandteil eines Präpositionalobjekts und kein Passivsubjekt) oder eine andere Klassifizierung sinnvoller wäre (z.B. “Was ist hier passiert?” - “was” wurde als Passivsubjekt des Verbs “passieren” eingeordnet). Im Untertitel “wenn du nicht gekommen wärst” scheint das Programm den sein-Passiv übergeneralisierend auf Sätze mit einem Verb im Perfekt anzuwenden. Einige Fehler kommen aufgrund unvollständiger Sätze als Input vor, andere wiederum aufgrund der Tatsache, dass bestimmte sprachliche Formen mehrere Funktionen in der Sprache erfüllen können.
avatar_words_udpiped %>%
select(sentence, upos, dep_rel, language) %>%
filter(language == "deu") %>%
filter(upos == "NOUN" | upos == "PRON") %>%
filter(str_detect(dep_rel, "nsubj:pass")) %>%
rmarkdown::paged_table()17.5.4 Objekt nominal / pronominal
Wird das direkte Objekt (obj), im Deutschen und Slowenischen auch Akkusativojekt genannt, in den Untertiteln häufiger nominal oder pronominal ausgedrückt?
x = avatar_words_udpiped %>%
group_by(language) %>%
filter(upos == "NOUN" | upos == "PRON") %>%
filter(dep_rel == "obj") %>%
count(upos, dep_rel) %>%
mutate(pct = round(100*n/sum(n),2)) %>%
pivot_wider(names_from = language, values_from = c(n, pct)) %>%
# mutate(across(everything(), ~ replace_na(.x, 0))) %>%
mutate_if(is.numeric, ~ replace_na(.x, 0)) %>%
arrange(upos)
x %>% rmarkdown::paged_table()Die Tabelle deutet daraufhin, dass in den englischen Untertiteln kein wesentlicher Unterschied auftritt, in den deutschen und slowenischen Untertiteln dagegen schon. Das können wir wiederum testen. Der erste Chi-Quadrat-Test bestätigt für die englischen Untertitel die Null-Hypothese (bei p > 0,05 also keinen Unterschied), für die deutschen und slowenischen Untertitel dagegen die alternative Hypothese (d.h. dass es bei p < 0,05 einen Wahrscheinlichkeitsunterschied gibt, ob das Objekt nominal oder pronominal ausgedrückt ist).
englisch = chisq.test(x[,4]) %>% tidy() %>% mutate(language = "eng")
deutsch = chisq.test(x[,3]) %>% tidy() %>% mutate(language = "deu")
slowenisch = chisq.test(x[,5]) %>% tidy() %>% mutate(language = "slv")
chisqtabelle = bind_rows(englisch, deutsch, slowenisch) %>%
select(language, statistic, p.value)
chisqtabelle %>% rmarkdown::paged_table()17.5.5 Wortklasse von Subjekt / Objekt
Welche sprachübergreifende (cross-linguistic) Tendenz werden mit den englisch- und deutschsprachigen Daten bestätigt?
avatar_words_udpiped %>%
group_by(language) %>%
filter(upos == "NOUN" | upos == "PRON") %>%
filter(dep_rel == "nsubj" | dep_rel == "obj") %>%
count(upos, dep_rel) %>%
# group_by(upos) %>%
mutate(pct = round(100*n/sum(n),2)) %>%
pivot_wider(names_from = language, values_from = c(n, pct)) %>%
# mutate(across(everything(), ~ replace_na(.x, 0))) %>%
mutate_if(is.numeric, ~ replace_na(.x, 0)) %>%
arrange(upos) %>%
rmarkdown::paged_table()Englisch:
pivot_by_obj <- function(tbl) {
tbl %>%
filter(upos == "NOUN" | upos == "PRON") %>%
filter(dep_rel == "nsubj" | dep_rel == "obj") %>%
count(upos, dep_rel) %>%
group_by(upos) %>%
mutate(pct = round(100*n/sum(n),2)) %>%
pivot_wider(names_from = upos, values_from = c(n, pct)) %>%
mutate_if(is.numeric, ~ replace_na(.x, 0))
# mutate(across(everything(), ~ replace_na(.x, 0)))
}
x = avatar_words_udpiped %>%
filter(language == "eng") %>%
pivot_by_obj()
x %>% rmarkdown::paged_table()Deutsch:
x = avatar_words_udpiped %>%
filter(language == "deu") %>%
pivot_by_obj()
x %>% rmarkdown::paged_table()Sowohl in den englischen als auch deutschen Untertiteln wird das Subjekt häufiger pronominal und seltener nominal ausgedrückt. Beim direkten Objekt ist es umgekehrt, denn dieses wird häufiger nominal ausgedrückt. Das man darauf zurückgeführen, dass das Subjekt häufig definit ist (etwas vom Hörer / Leser Identifizierbares ausdrückt), das Objekt dagegen etwas (noch) nicht Identifziertes.
Dieses Verhältnis können wir in den slowenischen Untertiteln nicht nachweisen, was wir wiederum auf die Tatsache zurückführen können, dass Slowenisch eine Pro-Drop-Sprachen ist und daher die Anzahl pronominalisierter Subjekte wesentlich geringer sein muss, da ein pronominalisiertes Subjekt nur bei Hervorhebung obligatorisch im Satz vorkommt.
x = avatar_words_udpiped %>%
filter(language == "slv") %>%
pivot_by_obj()
x %>% rmarkdown::paged_table()17.5.6 Gattungs- und Eigennamen
Treten Gattungsnamen (Appelativa) und Eigennamen häufiger in Subjekt- oder in Objekt-Funktion auf?
Englisch:
pivot_by_propn <- function(tbl) {
tbl %>%
filter(upos %in% c("NOUN", "PROPN")) %>%
filter(dep_rel == "nsubj" | dep_rel == "obj") %>%
count(upos, dep_rel) %>%
group_by(upos) %>%
mutate(pct = round(100*n/sum(n),2)) %>%
pivot_wider(names_from = upos, values_from = c(n, pct)) %>%
mutate_if(is.numeric, ~ replace_na(.x, 0))
# mutate(across(everything(), ~ replace_na(.x, 0)))
}
x = avatar_words_udpiped %>%
filter(language == "eng") %>%
pivot_by_propn()
x %>% rmarkdown::paged_table()Deutsch:
x = avatar_words_udpiped %>%
filter(language == "deu") %>%
pivot_by_propn()
x %>% rmarkdown::paged_table()Slowenisch:
x = avatar_words_udpiped %>%
filter(language == "slv") %>%
pivot_by_propn()
x %>% rmarkdown::paged_table()In allen drei Sprachversionen treten die Eigennamen (PROPN) häufiger in Subjekt-Funktion als in Objekt-Funktion auf, was man wieder darauf zurückführen kann, dass Eigennamen eine definite (d.h. identifizierbare) Einheit bezeichnen.
17.5.7 Konstituentenfolge
In SOV-Sprachen ist die Reihenfolge Modifizierer vor Kopf häufiger zu beobachten, in SVO-Sprachen dagegen Modifizierer nach Kopf. Das prüfen wir in unserem bisherigen Sprachmaterial. Als Modifizierer wählen wird attributive Adjektive, als Kopf von Nominalphrasen die davor oder dahinter stehenden Substantive oder andere Wortklassen (z.B. Pronomen).
Englisch und Slowenisch werden gewöhnlich als SVO-Sprachen eingeordnet, Deutsch mit der Konstituentenfolge SVO in Hauptsätzen und SOV in Nebensätzen wird im Atlas Wals (https://wals.info) dagegen als Sprache ohne dominante Konstituentenfolge bezeichnet.
Was zeigt nun unser Sprachmaterial?
avatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel == "amod" &
upos == "ADJ") %>%
mutate(word_order = ifelse(token_id < head_token_id,
"adj before head",
"adj after head")) %>%
count(dep_rel, word_order) %>%
mutate(pct = round(100*n/sum(n),2)) %>%
pivot_wider(names_from = language, values_from = c(n, pct)) %>%
# mutate(across(everything(), ~ replace_na(.x, 0))) %>%
mutate_if(is.numeric, ~ replace_na(.x, 0)) %>%
mutate(dep_rel =
str_replace(dep_rel, "0", "Unknown")) %>%
select(-dep_rel) %>%
rmarkdown::paged_table()Im Englischen, Deutschen und Slowenischen und Türkischen dominiert die Reihenfolge Adjektiv vor Substantiv, also Modifizierer vor Kopf. Im Französischen und Italienischen dagegen ist die umgekehrte Reihenfolge dominant bzw. sind sowohl vor- als auch nachgestellte adjektivische Attribute fast gleich gut vertreten.
Schauen wir uns noch an, in welchen Untertiteln unser Programm nachgestellte Adjektive identifiziert hat!
avatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel == "amod" &
upos == "ADJ") %>%
mutate(word_order = ifelse(token_id < head_token_id,
"adj before head",
"adj after head")) %>%
filter(word_order == "adj after head") %>%
ungroup() %>%
select(sentence, token, word_order, -language)## # A tibble: 276 x 3
## sentence token word_order
## <chr> <chr> <chr>
## 1 You could do something important. impo~ adj after~
## 2 There's nothing like an old-school safety brief to put your~ brief adj after~
## 3 I'm a man short. short adj after~
## 4 However, it does present an opportunity both timely and uni~ time~ adj after~
## 5 to the root of the tree next to it. next adj after~
## 6 Don't do anything unusually stupid. stup~ adj after~
## 7 There is something really interesting going on in there bio~ inte~ adj after~
## 8 - Stay down, sir. sir adj after~
## 9 I'm talking about something real, real adj after~
## 10 something measurable in the biology of the forest. meas~ adj after~
## # ... with 266 more rowsIm slowenischen Untertitel “Gre za nekaj resničnega” wird das Adjektiv “resničnega” als nachgestelltes Attribut zum Kopf “nekaj”, einem Pronomen, eingeordnet. Entsprechend im englischen Untertitel: “Something measurable”. Aber einige der Belege entpuppen sich als Fehlmeldung.
17.5.8 Kontexte von Modifizierern
avatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel == "amod" &
upos == "ADJ") %>%
mutate(word_order = ifelse(token_id < head_token_id,
"adj before head",
"adj after head")) %>%
filter(lemma == "big" | lemma == "groß" | lemma == "velik") %>%
ungroup() %>%
select(word_order, lemma, sentence)## # A tibble: 30 x 3
## word_order lemma sentence
## <chr> <chr> <chr>
## 1 adj before head big with a big hole blown through the middle of my life,
## 2 adj before head big I know it's a big inconvenience for everyone.
## 3 adj before head big Try and use big words.
## 4 adj before head big I might just give you a big wet kiss.
## 5 adj before head big That is one big damn tree.
## 6 adj before head big You big baby.
## 7 adj before head big Charlie 2-1, got big movement.
## 8 adj before head big Bravo 1-1, I got a big seating.
## 9 adj before head groß Möge die Große Mutter
## 10 adj before head groß dem größten Unobtanium-Vorkommen
## # ... with 20 more rowsavatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel == "amod" &
upos == "ADJ") %>%
mutate(word_order = ifelse(token_id < head_token_id,
"adj before head",
"adj after head")) %>%
filter(lemma == "big" | lemma == "groß" | lemma == "velik") %>%
count(lemma)## # A tibble: 3 x 3
## # Groups: language [3]
## language lemma n
## <chr> <chr> <int>
## 1 deu groß 11
## 2 eng big 8
## 3 slv velik 1117.5.9 Greenbergs Universalie 25
“If the pronominal object follows the verb, so does the nominal object.”
Zuerst wollen wir direkte Objekte (im Deutschen und Slowenischen auch als Akkusativobjekte bezeichnet) ausfinding machen, die sowohl Gattungsnamen als auch Eigennamen enthalten und die dem Kopf der Verbalphrase vorangehen (OV) oder folgen (VO).
pivot_by_verb_obj = function(tbl){
tbl %>%
mutate(word_order = ifelse(token_id > head_token_id,
"VO",
"OV")) %>%
count(dep_rel, word_order) %>%
mutate(pct = round(100*n/sum(n),2)) %>%
pivot_wider(names_from = language, values_from = c(n, pct)) %>%
# mutate(across(everything(), ~ replace_na(.x, 0))) %>%
mutate_if(is.numeric, ~ replace_na(.x, 0)) %>%
mutate(dep_rel =
str_replace(dep_rel, "0", "Unknown")) %>%
select(-dep_rel)
}
vo_nominal = avatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel == "obj" &
upos %in% c("NOUN", "PROPN")) %>%
pivot_by_verb_obj() %>%
mutate(word_class = "NOUN")Nun machen wir dasselbe mit den pronominalen Objekten.
vo_pronominal = avatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel == "obj" &
upos %in% c("PRON")) %>%
pivot_by_verb_obj() %>%
mutate(word_class = "PRON")Dann fügen wir beide Tabellen zusammen.
verb_object = bind_rows(vo_nominal, vo_pronominal) %>%
select(word_class, word_order:pct_tur)
verb_object %>% rmarkdown::paged_table()Unsere erste Abbildung der Verhältnisse in den sechs Sprachen.
verb_object %>%
select(word_class, word_order, pct_deu:pct_tur) %>%
pivot_longer(pct_deu:pct_tur,
names_to = "language", values_to = "pct") %>%
mutate(language = str_replace(language, "pct_", "")) %>%
ggplot(aes(pct, word_class, fill = word_order)) +
geom_col() +
facet_wrap(~ language) +
theme(legend.position = "top")
ggsave("pictures/barplot_avatar_VO-OV_NN_PRON.png")Die nächste Abbildung zeigt die Entfernung bzw. Ähnlichkeit der Sprachen ähnlich wie auf einer Landkarte an.
verb_object %>%
select(word_class, word_order, n_deu:n_tur) %>%
pivot_longer(n_deu:n_tur,
names_to = "language", values_to = "n") %>%
mutate(language = str_replace(language, "n_", "")) %>%
pivot_wider(names_from = c(word_order, word_class),
values_from = n) %>%
group_by(language) %>%
summarise(ov_nouns_prop = OV_NOUN/(VO_NOUN + OV_NOUN),
ov_prons_prop = OV_PRON/(VO_PRON + OV_PRON)) %>%
ggplot(aes(ov_nouns_prop, ov_prons_prop,
fill = language, group = language)) +
# geom_text(aes(label = language, check.overlap = TRUE)) +
geom_label(aes(label = language, check.overlap = TRUE)) +
theme(legend.position = "none") +
labs(x = "OV-Anteil bei Substantiven",
y = "OV-Anteil bei Pronomen")
ggsave("pictures/koord_avatar_VO-OV_NN_PRON.png") 17.5.10 Subjekt-vor-Objekt-Präferenz
17.5.10.1 SO-/OS-Anteil
Den Anteil der Subjekte und Objekte, nominal und pronominal ausgedrückt, kann man mit der folgenden Funktion berechnen.
pivot_by_obj <- function(tbl) {
tbl %>%
filter(upos == "NOUN" | upos == "PRON") %>%
filter(dep_rel == "nsubj" | dep_rel == "obj") %>%
count(upos, dep_rel) %>%
group_by(upos) %>%
mutate(pct = round(100*n/sum(n),2)) %>%
pivot_wider(names_from = upos, values_from = c(n, pct)) %>%
mutate_if(is.numeric, ~ replace_na(.x, 0))
# mutate(across(everything(), ~ replace_na(.x, 0)))
}
x = avatar_words_udpiped %>%
filter(language == "eng") %>%
pivot_by_obj()Die nächste Funktion prüft, in welcher Reihenfolge Subjekt, Objekt und Verb auftreten. Unterschieden werden sechs verschiedene Konstituentenfolgen:
- SVO, SOV, VSO, OVS, OSV und VOS.
Eine eingebaute Filterfunktion vereinfacht die Klassifizierung auf drei Klassen: SO (subjektinitialer Satz), OS (objektinitialer Satz) und “other”, da ähnliche graphische Darstellungen entstehen sollen wie oben im Zusammenhang mit der Verb-Objekt-Abfolge.
pivot_by_subj_verb_obj <- function(tbl) {
tbl %>%
filter(dep_rel %in% c("nsubj", "obj")) %>%
mutate(token_id_nsubj = ifelse(dep_rel %in% c("nsubj"), token_id, NA),
token_id_obj = ifelse(dep_rel %in% c("obj"), token_id, NA)) %>%
pivot_wider(c(doc_id:sentence, language, head_token_id),
names_from = dep_rel,
values_from = c(token_id),
values_fn = mean) %>%
mutate(word_order = case_when(
nsubj < obj & nsubj < head_token_id & obj > head_token_id ~ "SVO",
nsubj < obj & nsubj < head_token_id & obj < head_token_id ~ "SOV",
nsubj < obj & nsubj > head_token_id & obj > head_token_id ~ "VSO",
nsubj > obj & nsubj > head_token_id & obj < head_token_id ~ "OVS",
nsubj > obj & nsubj < head_token_id & obj < head_token_id ~ "OSV",
nsubj < obj & nsubj > head_token_id & obj > head_token_id ~ "VOS",
TRUE ~ "other"
)) %>%
# optional removal of "V" and other
mutate(word_order = str_remove(word_order, "V")) %>%
filter(word_order != "other") %>%
group_by(language) %>%
# no dep_rel anymore
# count(dep_rel, word_order) %>%
count(word_order) %>%
mutate(pct = round(100*n/sum(n),2)) %>%
pivot_wider(names_from = language, values_from = c(n, pct)) %>%
mutate_if(is.numeric, ~ replace_na(.x, 0))
# mutate(across(everything(), ~ replace_na(.x, 0))) #%>%
# mutate(dep_rel =
# str_replace(dep_rel, "0", "Unknown")) %>%
# select(-dep_rel)
}Berechnung der Anteile der beiden interessierenden Konstituentenfolgen (SO und OS) bei nominaler und pronominaler Ausdrucksweise:
svo_nominal = avatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel == "nsubj" | dep_rel == "obj") %>%
filter(upos %in% c("NOUN", "PROPN")) %>%
pivot_by_subj_verb_obj() %>%
mutate(word_class = "NOUN")
svo_pronominal = avatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel == "nsubj" | dep_rel == "obj") %>%
filter(upos %in% c("PRON")) %>%
pivot_by_subj_verb_obj() %>%
mutate(word_class = "PRON")
so_nom_pron = avatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel == "nsubj" | dep_rel == "obj") %>%
filter(upos %in% c("NOUN", "PROPN", "PRON")) %>%
pivot_by_subj_verb_obj() %>%
mutate(word_class = "NOUN")Beide Tabellen werden zu einer vereint.
subject_object = bind_rows(svo_nominal, svo_pronominal) %>%
select(word_class, word_order:pct_tur)
subject_object %>% rmarkdown::paged_table()In der ersten Abbildung verwenden wir liegende Säulendiagramme. Die relativ geringen Unterschiede zwischen den Sprachen waren zu erwarten, da nur SO-Sprachen ins Sample aufgenommen wurden.
subject_object %>%
filter(word_order == "SO" | word_order == "OS") %>%
select(word_class, word_order, pct_deu:pct_tur) %>%
pivot_longer(pct_deu:pct_tur,
names_to = "language", values_to = "pct") %>%
mutate(language = str_replace(language, "pct_", "")) %>%
ggplot(aes(pct, word_class, fill = word_order)) +
geom_col(position = "fill") +
scale_x_continuous(labels = percent_format(accuracy = 1)) +
labs(x = "") +
facet_wrap(~ language) +
theme(legend.position = "top")
ggsave("pictures/barplot_avatar_SO-OS_NN_PRON.png")Im zweiten Vergleich wählen wir wiederum eine landkartenähnliche Darstellungsweise. Da es sich um sechs Sprachen mit Subjekt-zuerst-Präferenz handelt, sind die Unterschiede relativ klein auf der Landkarte (besser zu sehen, wenn der Nullpunkt des Koordinaatensystems in die graphische Darstellung einbezogen ist - expand_limits()).
subject_object %>%
select(word_class, word_order, n_deu:n_tur) %>%
filter(word_order == "SO" | word_order == "OS") %>%
pivot_longer(n_deu:n_tur,
names_to = "language", values_to = "n") %>%
mutate(language = str_replace(language, "n_", "")) %>%
pivot_wider(names_from = c(word_order, word_class),
values_from = n) %>%
group_by(language) %>%
summarise(so_nouns_prop = SO_NOUN/(SO_NOUN + OS_NOUN),
so_prons_prop = SO_PRON/(SO_PRON + OS_PRON)) %>%
ggplot(aes(so_nouns_prop, so_prons_prop,
fill = language, group = language)) +
# geom_text(aes(label = language, check.overlap = TRUE)) +
geom_label(aes(label = language, check.overlap = TRUE)) +
theme(legend.position = "none") +
# expand_limits(x = 0, y = 0) +
scale_x_continuous(labels = percent_format(accuracy = 1)) +
scale_y_continuous(labels = percent_format(accuracy = 1)) +
labs(x = "SO-Anteil bei Substantiven",
y = "SO-Anteil bei Pronomen")
ggsave("pictures/koord_avatar_SO-SO_NN_PRON.png") 17.5.10.2 Belege für OS-Abfolgen
Wir wandeln die oben stehende Funktion pivot_by_subj_verb_obj() ein wenig ab, um zu erfahren, in welchen Sätzen OS-Abfolgen gemäß der automatischen Klassifizierung erscheinen.
pivot_by_subj_verb_obj_which <- function(tbl){
tbl %>%
filter(dep_rel %in% c("nsubj", "obj")) %>%
mutate(token_id_nsubj = ifelse(dep_rel %in% c("nsubj"), token_id, NA),
token_id_obj = ifelse(dep_rel %in% c("obj"), token_id, NA)) %>%
pivot_wider(c(doc_id:sentence, language, head_token_id),
names_from = dep_rel,
values_from = c(token_id),
values_fn = mean) %>%
mutate(word_order = case_when(
nsubj < obj & nsubj < head_token_id & obj > head_token_id ~ "SVO",
nsubj < obj & nsubj < head_token_id & obj < head_token_id ~ "SOV",
nsubj < obj & nsubj > head_token_id & obj > head_token_id ~ "VSO",
nsubj > obj & nsubj > head_token_id & obj < head_token_id ~ "OVS",
nsubj > obj & nsubj < head_token_id & obj < head_token_id ~ "OSV",
nsubj < obj & nsubj > head_token_id & obj > head_token_id ~ "VOS",
TRUE ~ "other"
)) %>%
# optional removal of "V" and other
mutate(word_order = str_remove(word_order, "V")) %>%
filter(word_order != "other") %>%
group_by(language)
}Deutsch: OS-Abfolge mit Nomen oder Pronomen
Eine Reihe von Fehlanzeigen!
Sätze mit zwei NPs im Nominativ (z.B. Die Starken jagen die Schwachen) sind morphosyntaktisch nicht eindeutig bestimmbar. Menschen würden in den meisten Fällen die NP die Starken als Subjekt bestimmen, weil es zuerst genannt wird und weil unsere Erfahrungen das für wahrscheinlicher halten.
Sätze wie wenn ihr die Maske verliert, d.h. mit angesprochenem Subjekt (ihr), scheinen auch für Probleme zu sorgen.
avatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel == "nsubj" | dep_rel == "obj") %>%
# filter(upos %in% c("NOUN", "PROPN")) %>%
pivot_by_subj_verb_obj_which() %>%
filter(language == "deu") %>%
ungroup() %>%
select(sentence, obj, nsubj, word_order, -language) %>%
filter(word_order == "OS")## # A tibble: 65 x 4
## sentence obj nsubj word_order
## <chr> <dbl> <dbl> <chr>
## 1 Die Starken jagen die Schwachen. 2 5 OS
## 2 Die Starken jagen die Schwachen. 2 5 OS
## 3 Tommy war der Wissenschaftler, nicht ich. 1 4 OS
## 4 Denkt dran, wenn ihr die Maske verliert, 5 7 OS
## 5 So was wie einen Ex-Marine gibt es nicht. 2 7 OS
## 6 aber die Einstellung verliert man nie. 3 5 OS
## 7 Oh, Mann, das gibt's doch gar nicht! 1 7 OS
## 8 Was wir sehen, was wir fühlen. 1 2 OS
## 9 Was wir sehen, was wir fühlen. 5 6 OS
## 10 Sie mag Pflanzen nämlich lieber 1 3 OS
## # ... with 55 more rowsSlowenisch: OS-Abfolge mit Nomen oder Pronomen
Geringerer Fehleranteil als in den deutschen Belegen.
Das Gentivobjekt naših navad wurde als Subjekt klassifiziert, das Subjekt moja hči übersehen.
Das negierte Subjekt nihče wurde nicht erkannt.
avatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel == "nsubj" | dep_rel == "obj") %>%
# filter(upos %in% c("NOUN", "PROPN")) %>%
pivot_by_subj_verb_obj_which() %>%
filter(language == "slv") %>%
ungroup() %>%
select(sentence, obj, nsubj, word_order, -language) %>%
filter(word_order == "OS")## # A tibble: 15 x 4
## sentence obj nsubj word_order
## <chr> <dbl> <dbl> <chr>
## 1 Me slišiš, Jake? 1 4 OS
## 2 Ste me iskali, polkovnik? 2 5 OS
## 3 Kaj delaš, Tsu'tey? 1 4 OS
## 4 Moja hči te bo učila naših navad. 2 7 OS
## 5 ko ga je lovil razdražen thanator. 2 6 OS
## 6 ugotovi, kaj hočejo te modre opice. 3 7 OS
## 7 Kaj to pomeni? 1 2 OS
## 8 ki ga mora opraviti vsak mlad lovec. 2 7 OS
## 9 Naši mu rečejo veliki leonopteriks. 2 5 OS
## 10 Tem drevesom rečemo Utraya Mokri. 2 5 OS
## 11 Nocoj prvo rundo plačam jaz. 3 5 OS
## 12 Veš, kaj to pomeni. 3 4 OS
## 13 Nihče mu ni nič mogel. 2 2.5 OS
## 14 Recite jim, da jih kliče Toruk Macto. 5 7 OS
## 15 Ko jih je Toruk Macto poklical, so prišli. 2 4 OSDeutsch: OS-Abfolge mit Nomen
Hier erweist sich, dass Udpipe die Satzglieder nicht einwandfrei identifizieren konnte. Fehler!
avatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel == "nsubj" | dep_rel == "obj") %>%
filter(upos %in% c("NOUN", "PROPN")) %>%
pivot_by_subj_verb_obj_which() %>%
filter(language == "deu") %>%
ungroup() %>%
select(sentence, obj, nsubj, word_order, -language) %>%
filter(word_order == "OS")## # A tibble: 3 x 4
## sentence obj nsubj word_order
## <chr> <dbl> <dbl> <chr>
## 1 Die Starken jagen die Schwachen. 2 5 OS
## 2 Die Starken jagen die Schwachen. 2 5 OS
## 3 Tommy war der Wissenschaftler, nicht ich. 1 4 OSDeutsch: OS-Abfolge mit Pronomen
Besser. Aber einige Fehler in der Analyse.
avatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel == "nsubj" | dep_rel == "obj") %>%
filter(upos %in% c("PRON")) %>%
pivot_by_subj_verb_obj_which() %>%
filter(language == "deu") %>%
ungroup() %>%
select(sentence, obj, nsubj, word_order, -language) %>%
filter(word_order == "OS")## # A tibble: 45 x 4
## sentence obj nsubj word_order
## <chr> <dbl> <dbl> <chr>
## 1 So was wie einen Ex-Marine gibt es nicht. 2 7 OS
## 2 Was wir sehen, was wir fühlen. 1 2 OS
## 3 Was wir sehen, was wir fühlen. 5 6 OS
## 4 Das haben Sie nicht. 1 3 OS
## 5 Das Letzte, was ich da brauche, 4 5 OS
## 6 Was haben Sie sich dabei gedacht? 2.5 3 OS
## 7 Die betäuben Sie sonst. 1 3 OS
## 8 - Wen haben Sie erwartet, Sie Dumpfbacke? 2 4 OS
## 9 Mir fehlt jemand. 1 3 OS
## 10 Besorgen Sie mir, was ich brauche, 5 6 OS
## # ... with 35 more rowsSlowenisch: OS-Abfolge mit Nomen
Fehler in beiden Belegen!
Im ersten Beleg: Moja hči ist das Subjekt, das klitisierte Pronomen te das Objekt. Fälschlicherweise wird das Genitivobjekt naših navad als Subjekt analysiert.
Im zweiten Beleg ist das Subjekt nur (implizit) in der finiten Verbform rečemo enthalten. Das Dativobjekt tem drevesom steht vor der finiten Verbform. Fälschlicherweise wird die Phrase Utraya Mokri (x nennt man so. Wie nennt man x ?) als Subjekt klassifiziert statt als Prädikativ oder Adverbialbestimmung.
avatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel == "nsubj" | dep_rel == "obj") %>%
filter(upos %in% c("NOUN", "PROPN")) %>%
pivot_by_subj_verb_obj_which() %>%
filter(language == "slv") %>%
ungroup() %>%
select(sentence, obj, nsubj, word_order, -language) %>%
filter(word_order == "OS")## # A tibble: 2 x 4
## sentence obj nsubj word_order
## <chr> <dbl> <dbl> <chr>
## 1 Moja hči te bo učila naših navad. 2 7 OS
## 2 Tem drevesom rečemo Utraya Mokri. 2 5 OSSlowenisch: OS-Abfolge mit Pronomen
Besser. Aber einige Fehler in der Analyse.
avatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel == "nsubj" | dep_rel == "obj") %>%
filter(upos %in% c("PRON")) %>%
pivot_by_subj_verb_obj_which() %>%
filter(language == "slv") %>%
ungroup() %>%
select(sentence, obj, nsubj, word_order, -language) %>%
filter(word_order == "OS")## # A tibble: 1 x 4
## sentence obj nsubj word_order
## <chr> <dbl> <dbl> <chr>
## 1 Nihče mu ni nič mogel. 2 2.5 OS17.5.11 Mehrere Konstituenten
# avatar_words_udpiped %>% filter(language == "deu")pivot_by_constituents <- function(tbl) {
tbl %>%
filter(dep_rel %in% c("nsubj", "obj", "advmod",
"aux", "cop", "root")) %>%
mutate(token_id_nsubj = ifelse(dep_rel %in% c("nsubj"), token_id, NA),
token_id_obj = ifelse(dep_rel %in% c("obj"), token_id, NA),
token_id_advmod = ifelse(dep_rel %in% c("advmod"), token_id, NA),
token_id_cop = ifelse(dep_rel %in% c("cop"), token_id, NA),
token_id_root = ifelse(dep_rel %in% c("root"), token_id, NA),
token_id_aux = ifelse(dep_rel %in% c("aux"), token_id, NA)) %>%
pivot_wider(c(doc_id:sentence, language, head_token_id),
names_from = dep_rel,
values_from = c(token_id),
values_fn = mean) %>%
mutate(word_order = case_when(
advmod < aux & aux < nsubj &
nsubj < obj & nsubj < head_token_id & obj > head_token_id ~ "AaSVO",
advmod < aux & aux < nsubj &
nsubj < obj & nsubj < head_token_id & obj < head_token_id ~ "AaSOV",
advmod < nsubj &
nsubj < obj & nsubj < head_token_id & obj > head_token_id ~ "ASVO",
advmod < nsubj &
nsubj < obj & nsubj < head_token_id & obj < head_token_id ~ "ASOV",
advmod < head_token_id &
nsubj < obj & nsubj > head_token_id & obj > head_token_id ~ "AVSO",
advmod < obj &
nsubj > obj & nsubj > head_token_id & obj < head_token_id ~ "AOVS",
advmod < obj &
nsubj > obj & nsubj < head_token_id & obj < head_token_id ~ "AOSV",
advmod < head_token_id &
nsubj < obj & nsubj > head_token_id & obj > head_token_id ~ "AVOS",
nsubj < obj & nsubj < head_token_id & obj > head_token_id ~ "SVO",
nsubj < obj & nsubj < head_token_id & obj < head_token_id ~ "SOV",
nsubj < obj & nsubj > head_token_id & obj > head_token_id ~ "VSO",
nsubj > obj & nsubj > head_token_id & obj < head_token_id ~ "OVS",
nsubj > obj & nsubj < head_token_id & obj < head_token_id ~ "OSV",
nsubj < obj & nsubj > head_token_id & obj > head_token_id ~ "VOS",
TRUE ~ "other"
)) %>%
# optional removal of "V" and other
# mutate(word_order = str_remove(word_order, "V")) %>%
filter(word_order != "other") %>%
group_by(language) %>%
# no dep_rel anymore
# count(dep_rel, word_order) %>%
count(word_order) %>%
mutate(pct = round(100*n/sum(n),2)) %>%
pivot_wider(names_from = language, values_from = c(n, pct)) %>%
mutate_if(is.numeric, ~ replace_na(.x, 0))
# mutate(across(everything(), ~ replace_na(.x, 0))) #%>%
# mutate(dep_rel =
# str_replace(dep_rel, "0", "Unknown")) %>%
# select(-dep_rel)
}asvo_nom_pron <- avatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel %in% c("nsubj", "obj", "advmod", "aux", "cop", "root")) %>%
filter(upos %in% c("NOUN", "PROPN", "PRON", "ADV", "AUX")) %>%
pivot_by_constituents() %>%
mutate(word_class = "differs")
asvo_nom_pron## # A tibble: 12 x 14
## word_order n_deu n_eng n_fra n_ita n_slv n_tur pct_deu pct_eng pct_fra
## <chr> <int> <int> <int> <int> <int> <int> <dbl> <dbl> <dbl>
## 1 AaSOV 7 1 0 0 0 0 1.56 0.29 0
## 2 ASOV 2 0 3 1 0 0 0.45 0 1.08
## 3 ASVO 2 16 3 1 0 1 0.45 4.6 1.08
## 4 AVSO 12 0 1 1 0 0 2.67 0 0.36
## 5 OSV 34 22 14 2 2 14 7.57 6.32 5.04
## 6 OVS 31 0 8 8 11 7 6.9 0 2.88
## 7 SOV 124 1 75 17 11 29 27.6 0.29 27.0
## 8 SVO 186 306 172 49 20 2 41.4 87.9 61.9
## 9 VSO 51 0 0 0 0 0 11.4 0 0
## 10 AaSVO 0 1 0 0 0 0 0 0.29 0
## 11 AOSV 0 1 0 0 0 0 0 0.29 0
## 12 AOVS 0 0 2 0 0 0 0 0 0.72
## # ... with 4 more variables: pct_ita <dbl>, pct_slv <dbl>, pct_tur <dbl>,
## # word_class <chr>pivot_by_constituents_which <- function(tbl){
tbl %>%
filter(dep_rel %in% c("nsubj", "obj", "advmod",
"aux", "cop", "root")) %>%
mutate(token_id_nsubj = ifelse(dep_rel %in% c("nsubj"), token_id, NA),
token_id_obj = ifelse(dep_rel %in% c("obj"), token_id, NA),
token_id_advmod = ifelse(dep_rel %in% c("advmod"), token_id, NA),
token_id_cop = ifelse(dep_rel %in% c("cop"), token_id, NA),
token_id_root = ifelse(dep_rel %in% c("root"), token_id, NA),
token_id_aux = ifelse(dep_rel %in% c("aux"), token_id, NA)) %>%
pivot_wider(c(doc_id:sentence, language, head_token_id),
names_from = dep_rel,
values_from = c(token_id),
values_fn = mean) %>%
mutate(word_order = case_when(
advmod < aux & aux < nsubj &
nsubj < obj & nsubj < head_token_id & obj > head_token_id ~ "AaSVO",
advmod < aux & aux < nsubj &
nsubj < obj & nsubj < head_token_id & obj < head_token_id ~ "AaSOV",
advmod < nsubj &
nsubj < obj & nsubj < head_token_id & obj > head_token_id ~ "ASVO",
advmod < nsubj &
nsubj < obj & nsubj < head_token_id & obj < head_token_id ~ "ASOV",
advmod < head_token_id &
nsubj < obj & nsubj > head_token_id & obj > head_token_id ~ "AVSO",
advmod < obj &
nsubj > obj & nsubj > head_token_id & obj < head_token_id ~ "AOVS",
advmod < obj &
nsubj > obj & nsubj < head_token_id & obj < head_token_id ~ "AOSV",
advmod < head_token_id &
nsubj < obj & nsubj > head_token_id & obj > head_token_id ~ "AVOS",
nsubj < obj & nsubj < head_token_id & obj > head_token_id ~ "SVO",
nsubj < obj & nsubj < head_token_id & obj < head_token_id ~ "SOV",
nsubj < obj & nsubj > head_token_id & obj > head_token_id ~ "VSO",
nsubj > obj & nsubj > head_token_id & obj < head_token_id ~ "OVS",
nsubj > obj & nsubj < head_token_id & obj < head_token_id ~ "OSV",
nsubj < obj & nsubj > head_token_id & obj > head_token_id ~ "VOS",
TRUE ~ "other"
)) %>%
# optional removal of "V" and other
# mutate(word_order = str_remove(word_order, "V")) %>%
filter(word_order != "other") %>%
group_by(language)
}avatar_words_udpiped %>%
group_by(language) %>%
filter(dep_rel %in% c("nsubj", "obj", "advmod", "aux", "cop", "root")) %>%
filter(upos %in% c("PRON", "NOUN", "ADV", "VERB", "AUX")) %>%
pivot_by_constituents_which() %>%
filter(language == "deu") %>%
ungroup() %>%
select(sentence, obj, nsubj, word_order, -language) %>%
filter(word_order %in% c("AaSOV", "AaSVO", "ASVO", "ASOV", "AVSO"))## # A tibble: 23 x 4
## sentence obj nsubj word_order
## <chr> <dbl> <dbl> <chr>
## 1 Hier werden wir viel Zeit verbringen. 5 3 AaSOV
## 2 Hier verlinken wir uns mit den Avataren. 4 3 AVSO
## 3 und irgendwann vertrauen sie uns. 5 4 AVSO
## 4 Also nutzen Sie Ihre Möglichkeiten 5 3 AVSO
## 5 Wie fühlen Sie sich, Jake? 4 3 AVSO
## 6 aber Sie berichten mir. 4 2 ASVO
## 7 Vielleicht kann ich was von dir lernen. 4 3 AaSOV
## 8 Wo hast du unsere Sprache gelernt? 5 3 AaSOV
## 9 warum bringst du sie zu uns? 4 3 AVSO
## 10 aber es gab ein Zeichen von Eywa. 5 2 ASVO
## # ... with 13 more rows17.5.11.1 Zusätzliche graphische Darstellungen
Übersichtsgraphik mit Korrelationsberechnung:
library(GGally)
ggpairs(verb_object[,c(1:8)])
Korrelationsgraphik:
library(correlation)
library(see)
results = summary(correlation(verb_object[,c(1:8)]))
p = plot(results)
p + scale_fill_material_c(palette = "rainbow") + theme_abyss()
library(ggpage)
avatar_deu[1:100] %>%
ggpage_build() %>%
mutate(long_word = stringr::str_length(word) > 8) %>%
ggpage_plot(aes(fill = long_word)) +
labs(title = "Longer words throughout the Avatar subtitles") +
scale_fill_manual(values = c("grey70", "blue"),
labels = c("8 or less", "9 or more"),
name = "Word length")
library(ggwordcloud)
library(tidytext)
stoplist_eng = as_tibble(c("not","hey","yeah","to","go","get")) %>%
rename(word = value)
x = avatar_words_udpiped %>%
filter(language == "eng") %>%
anti_join(stop_words) %>%
# anti_join(stoplist_eng) %>%
# filter(!lemma %in% c(stoplist_eng)) %>%
filter(!str_detect(lemma, c("not","hey","yeah","to","go","get"))) %>%
count(lemma, sort = TRUE)
x %>% ggplot(aes(label = lemma, size = n)) +
geom_text_wordcloud() +
scale_size_area(max_size = 40) +
theme_minimal()
Schnell eine Graphik mit dem Datensatz erstellen, ohne zu programmieren: