Kapitel 16 Lesbarkeitsindices
(Reading ease indices)
16.1 Zur theoretischen Begründung
“Lesbarkeitsformeln sind in der Forschung weitgehend etabliert. Viele, die sich mit Lesbarkeitsformeln befassen, stellen sich dennoch die Frage, wieso man bei Berücksichtigung nur sehr weniger Kriterien Aufschluss über die Lesbarkeit von Texten erhalten kann. Man hat ja doch leicht den Eindruck, dass Wort- und Satzlänge keine besonders triftigen Kriterien sein sollten. Schaut man sich aber an, mit welchen anderen Kriterien diese beiden genannten – und andere – verknüpft sind, kann man erkennen, dass zwar nur zwei Texteigenschaften direkt gemessen werden, damit aber indirekt eine ganze Reihe andere ebenfalls berücksichtigt werden.” — https://de.wikipedia.org/wiki/Lesbarkeitsindex
16.2 Programme
library(tidyverse)
library(tidytext)
library(quanteda)
library(readtext)
library(nsyllable)16.3 Texte lesen
stringsAsFactor = F
prozess = read_lines("novels/book05.txt")
enfants = read_lines("novels/book12.txt")
romane = readtext("novels/*.txt")
coronavirus2020 <- readtext("news/*.json",
text_field = "text", encoding = "LATIN1")16.4 Flesch Reading Ease - deutsche Version
knitr::include_graphics(
"pictures/Lesbarkeitsindex Flesch Ease deutsch.png")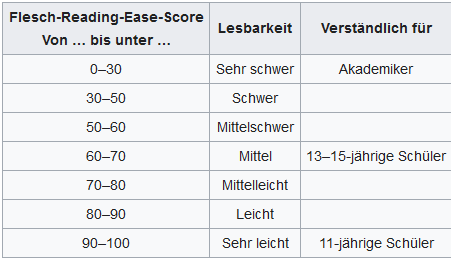
flres_de = readxl::read_xlsx("data/Flesch-Reading-Ease-Score-deutsch.xlsx")
flres_de %>%
mutate(`Verständlich für` = replace_na(`Verständlich für`," ")) %>%
rmarkdown::paged_table()16.5 Romane (deutsche oder ins Deutsche übersetzte)
lesbarkeitsindex_romane = as_tibble(romane) %>%
mutate(sentences = nsentence(text),
words = ntoken(text, remove_punct = TRUE),
syllables = nsyllable(text),
flesch_ease_de = 180 - (words/sentences) - 58.5*(syllables/words))
lesbarkeitsindex_romane %>%
select(doc_id, syllables, sentences, words, flesch_ease_de) %>%
arrange(flesch_ease_de) %>%
rmarkdown::paged_table()# write_excel_csv2(lesbarkeitsindex_romane, "data/lesbarkeitsindex_romane.csv")lesbarkeitsindex_romane = lesbarkeitsindex_romane %>%
mutate(book_name = str_sub(text, 1, 12)) # extract string in position 1-12
# reading score chart
ggplot(lesbarkeitsindex_romane, aes(x = syllables/words, y = flesch_ease_de,
color = book_name, name = book_name,
size = sentences)) +
geom_count(alpha = 0.5) +
# scale_x_log10() +
geom_smooth(se = FALSE, color = "red", method = "lm", size = 0.5,
linetype = "dashed") +
scale_y_continuous(breaks = c(60,65,70,75,80,85)) +
scale_x_continuous(breaks = c(1.3,1.4,1.5,1.6)) +
scale_size_area(max_size = 12, guide = FALSE) +
theme_minimal(base_size = 14) +
labs(color = "Roman", x = "# Silben pro Wort", y = "Lesbarkeitsindex")
book <- book[str_sub(book, 1, 12) == “review/text:”] # extract string in position 1-12 book <- str_sub(book, start = 14) # extract substring starting in position 14
library(plotly)
p <- lesbarkeitsindex_romane %>%
ggplot(aes(syllables/words, flesch_ease_de,
color = book_name, name = book_name, size = sentences)) +
geom_count() +
geom_smooth(se = FALSE, color = "red", method = "lm", size = 0.5,
linetype = "dashed") +
scale_y_continuous(breaks = c(60,65,70,75,80,85)) +
scale_x_continuous(breaks = c(1.3,1.4,1.5,1.6)) +
scale_size_area(max_size = 12, guide = FALSE) +
theme_minimal(base_size = 14) +
labs(color = "Roman", x = "# Silben pro Wort", y = "Lesbarkeitsindex")
ggplotly(p, height = 500)16.6 Zeitungen
lesbarkeitsindex_news = as_tibble(coronavirus2020) %>%
mutate(syllables = nsyllable(text),
sentences = nsentence(text),
words = ntoken(text, remove_punct = TRUE),
flesch_ease_de = 180 - (words/sentences) - 58.5*(syllables/words))
lesbarkeitsindex_news %>%
select(doc_id, syllables, sentences, words, flesch_ease_de) %>%
arrange(flesch_ease_de) %>%
rmarkdown::paged_table()# write_excel_csv2(lesbarkeitsindex_news,
# "data/lesbarkeitsindex_news_coronavirus_2020.csv")# reading score chart
ggplot(lesbarkeitsindex_news, aes(x = syllables/words, y = flesch_ease_de,
color = lubridate::month(date),
size = sentences)) +
geom_count(alpha = 0.5) +
geom_jitter() +
# scale_x_log10() +
geom_smooth(se = FALSE, color = "red", method = "lm", size = 0.5,
linetype = "dashed") +
scale_y_continuous(breaks = c(20,30,40,50,60,70,80,90,100)) +
scale_x_continuous(limits = c(1,2.5), breaks = c(1.0,1.25,1.5,1.75,2.0,2.25,2.5)) +
scale_size_area(max_size = 12, guide = "none") +
theme_minimal(base_size = 14) +
labs(color = "month 2020", x = "# Syllables per word", y = "Reading level")
lesbarkeitsindex_news = lesbarkeitsindex_news %>% mutate(news_name = str_sub(doc_id, 1, 7))
# reading score chart
ggplot(lesbarkeitsindex_news, aes(x = syllables/words, y = flesch_ease_de,
color = news_name,
name = news_name,
size = sentences)) +
geom_count(alpha = 0.5) +
geom_jitter() +
scale_y_continuous(breaks = c(20,30,40,50,60,70,80,90,100)) +
scale_x_continuous(limits = c(1,2.5), breaks = c(1,1.5,2.0,2.5)) +
facet_wrap(~ news_name) +
geom_smooth(se = FALSE, color = 1, method = "lm", size = 0.5,
linetype = "dashed") +
scale_size_area(max_size = 12, guide = "none") +
theme_light(base_size = 14) +
labs(color = "Zeitung", x = "# Silben pro Wort", y = "Lesbarkeitsindex")
library(plotly)
q = lesbarkeitsindex_news %>%
ggplot(aes(syllables/words, flesch_ease_de,
color = lubridate::month(date), name = news_name, size = sentences)) +
geom_point() +
facet_wrap(~ news_name) +
geom_jitter() +
geom_smooth(se = FALSE, color = "black", method = "lm", size = 0.5,
linetype = "dashed") +
scale_y_continuous(breaks = c(20,30,40,50,60,70,80,90,100)) +
scale_x_continuous(limits = c(1,2.5), breaks = c(1,1.5,2.0,2.5)) +
scale_size_area(max_size = 12, guide = "none") +
theme_light(base_size = 14) +
labs(color = "month 2020", x = "# Silben pro Wort", y = "Lesbarkeitsindex")
ggplotly(q, height = 500)16.7 Statistische Tests: News
Können wir statistisch signifikante Unterschiede zwischen den Lesbarkeitsindices nachweisen?
Mit dem t-Test können wir immer nur zwei Stichproben miteinander vergleichn.
lesbarkeitsindex_news %>%
filter(news_name != "welt_co" & news_name != "stern_g" & news_name != "focus_c") %>%
t.test(flesch_ease_de ~ news_name, data = ., paired = F, var.equal = T)##
## Two Sample t-test
##
## data: flesch_ease_de by news_name
## t = -10.532, df = 4924, p-value < 2.2e-16
## alternative hypothesis: true difference in means between group faz_cor and group spiegel is not equal to 0
## 95 percent confidence interval:
## -3.313378 -2.273477
## sample estimates:
## mean in group faz_cor mean in group spiegel
## 50.62753 53.42096lesbarkeitsindex_news %>%
filter(news_name != "spiegel" & news_name != "stern_g" & news_name != "focus_c") %>%
t.test(flesch_ease_de ~ news_name, data = ., paired = F, var.equal = T)##
## Two Sample t-test
##
## data: flesch_ease_de by news_name
## t = -13.358, df = 4215, p-value < 2.2e-16
## alternative hypothesis: true difference in means between group faz_cor and group welt_co is not equal to 0
## 95 percent confidence interval:
## -4.819682 -3.586028
## sample estimates:
## mean in group faz_cor mean in group welt_co
## 50.62753 54.83038lesbarkeitsindex_news %>%
filter(news_name != "faz_cor" & news_name != "stern_g" & news_name != "focus_c") %>%
t.test(flesch_ease_de ~ news_name, data = ., paired = F, var.equal = T)##
## Two Sample t-test
##
## data: flesch_ease_de by news_name
## t = -6.1477, df = 5941, p-value = 8.374e-10
## alternative hypothesis: true difference in means between group spiegel and group welt_co is not equal to 0
## 95 percent confidence interval:
## -1.8588644 -0.9599905
## sample estimates:
## mean in group spiegel mean in group welt_co
## 53.42096 54.83038Eine lineare Regression ermöglicht den Vergleich von mehreren Stichproben und mehreren Variablen (Faktoren, Prädiktoren).
lesbarkeitsindex_news %>%
lm(flesch_ease_de ~ news_name, data = .) %>%
summary()##
## Call:
## lm(formula = flesch_ease_de ~ news_name, data = .)
##
## Residuals:
## Min 1Q Median 3Q Max
## -68.487 -5.290 -0.583 5.397 53.357
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 50.6275 0.2255 224.481 <2e-16 ***
## news_namefocus_c -0.6147 2.3402 -0.263 0.793
## news_namespiegel 2.7934 0.2745 10.178 <2e-16 ***
## news_namestern_g 11.2601 0.4856 23.187 <2e-16 ***
## news_namewelt_co 4.2029 0.2863 14.680 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 9.021 on 7993 degrees of freedom
## Multiple R-squared: 0.06919, Adjusted R-squared: 0.06872
## F-statistic: 148.5 on 4 and 7993 DF, p-value: < 2.2e-1616.8 Datensätze vereinen
lesbarkeitsindex = lesbarkeitsindex_romane %>%
mutate(book_name = "romane") %>%
rename(news_name = book_name) %>%
bind_rows(lesbarkeitsindex_news[,c(1:2,7:11)])(les_mean = mean(lesbarkeitsindex$flesch_ease_de))## [1] 53.81142(les_sd = sd(lesbarkeitsindex$flesch_ease_de))## [1] 9.375399(syl_mean = mean(lesbarkeitsindex$syllables/lesbarkeitsindex$words))## [1] 1.875349library(plotly)
p <- lesbarkeitsindex %>%
ggplot(aes(syllables/words, flesch_ease_de,
color = news_name, name = news_name, size = sentences)) +
geom_count() +
geom_smooth(se = FALSE, color = "red", method = "lm", size = 0.5,
linetype = "dashed") +
geom_vline(xintercept = syl_mean, lty = 2) +
geom_hline(yintercept = les_mean, lty = 2) +
geom_hline(yintercept = les_mean + 2*les_sd, lty = 3) +
geom_hline(yintercept = les_mean - 2*les_sd, lty = 3) +
scale_y_continuous(
breaks = c(0,10,20,30,40,50,60,70,80,90,100,110)) +
scale_x_continuous(
breaks = c(1.0,1.2,1.4,1.6,1.8,2.0,2.2,2.4,2.6)) +
scale_size_area(max_size = 12, guide = "none") +
theme_minimal(base_size = 14) +
labs(color = "Medium", x = "# Silben pro Wort", y = "Lesbarkeitsindex")
ggplotly(p, height = 400)16.9 Zeitungen im Vergleich
# global options
# options(contrasts=c('contr.sum','contr.poly'))
lesbarkeitsindex$news_name = as.factor(lesbarkeitsindex$news_name)
# set contrast to "contr.sum"
contrasts(lesbarkeitsindex$news_name) <- "contr.sum"
contrasts(lesbarkeitsindex$news_name) # take a look## [,1] [,2] [,3] [,4] [,5]
## faz_cor 1 0 0 0 0
## focus_c 0 1 0 0 0
## romane 0 0 1 0 0
## spiegel 0 0 0 1 0
## stern_g 0 0 0 0 1
## welt_co -1 -1 -1 -1 -1lesbarkeitsindex %>%
lm(flesch_ease_de ~ news_name, data = .) %>%
summary()##
## Call:
## lm(formula = flesch_ease_de ~ news_name, data = .)
##
## Residuals:
## Min 1Q Median 3Q Max
## -68.487 -5.290 -0.581 5.397 53.357
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 57.2894 0.5892 97.241 < 2e-16 ***
## news_name1 -6.6618 0.6173 -10.793 < 2e-16 ***
## news_name2 -7.2765 1.9908 -3.655 0.000259 ***
## news_name3 15.6675 2.2062 7.102 1.34e-12 ***
## news_name4 -3.8684 0.6028 -6.417 1.47e-10 ***
## news_name5 4.5982 0.6858 6.705 2.16e-11 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 9.02 on 8004 degrees of freedom
## Multiple R-squared: 0.07494, Adjusted R-squared: 0.07436
## F-statistic: 129.7 on 5 and 8004 DF, p-value: < 2.2e-16lesbarkeitsindex %>%
lm(flesch_ease_de ~ news_name, data = .) %>%
tidy() %>%
# filter(term != "(Intercept)") %>%
mutate(term = str_replace(term, "news_name", "")) %>%
arrange(estimate)## # A tibble: 6 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 2 -7.28 1.99 -3.66 2.59e- 4
## 2 1 -6.66 0.617 -10.8 5.71e-27
## 3 4 -3.87 0.603 -6.42 1.47e-10
## 4 5 4.60 0.686 6.70 2.16e-11
## 5 3 15.7 2.21 7.10 1.34e-12
## 6 (Intercept) 57.3 0.589 97.2 0# global default option
# options(contrasts=c('contr.treatment','contr.poly'))
# set contrast back to default ("contr.treatment")
contrasts(lesbarkeitsindex$news_name) <- NULL
contrasts(lesbarkeitsindex$news_name) # take a look## focus_c romane spiegel stern_g welt_co
## faz_cor 0 0 0 0 0
## focus_c 1 0 0 0 0
## romane 0 1 0 0 0
## spiegel 0 0 1 0 0
## stern_g 0 0 0 1 0
## welt_co 0 0 0 0 1lesbarkeitsindex %>%
lm(flesch_ease_de ~ news_name, data = .) %>%
summary()##
## Call:
## lm(formula = flesch_ease_de ~ news_name, data = .)
##
## Residuals:
## Min 1Q Median 3Q Max
## -68.487 -5.290 -0.581 5.397 53.357
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 50.6275 0.2255 224.511 <2e-16 ***
## news_namefocus_c -0.6147 2.3399 -0.263 0.793
## news_nameromane 22.3293 2.6136 8.543 <2e-16 ***
## news_namespiegel 2.7934 0.2744 10.179 <2e-16 ***
## news_namestern_g 11.2601 0.4856 23.190 <2e-16 ***
## news_namewelt_co 4.2029 0.2863 14.682 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 9.02 on 8004 degrees of freedom
## Multiple R-squared: 0.07494, Adjusted R-squared: 0.07436
## F-statistic: 129.7 on 5 and 8004 DF, p-value: < 2.2e-16lesbarkeitsindex %>%
lm(flesch_ease_de ~ news_name, data = .) %>%
tidy() %>%
# filter(term != "(Intercept)") %>%
mutate(term = str_replace(term, "news_name", ""),
term = str_replace(term, "(Intercept)", "faz_cor")) %>%
arrange(estimate)## # A tibble: 6 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 focus_c -0.615 2.34 -0.263 7.93e- 1
## 2 spiegel 2.79 0.274 10.2 3.46e- 24
## 3 welt_co 4.20 0.286 14.7 3.53e- 48
## 4 stern_g 11.3 0.486 23.2 3.37e-115
## 5 romane 22.3 2.61 8.54 1.54e- 17
## 6 (faz_cor) 50.6 0.226 225. 0library(effects)
lesbarkeitsindex %>%
lm(flesch_ease_de ~ news_name, data = .) -> mymodel
plot(allEffects(mymodel))
16.10 Alle Texte im Vergleich
Die ausgewählten zwölf Romane haben einen deutlich höheren Lesbarkeitsindex als die Zeitungstexte. Woran liegt das: an der Wortlänge, der Silbenanzahl oder an der Satzlänge?
lesbarkeitsindex %>%
mutate(wordnum_utterance = (words/sentences),
sylnum_utterance = (syllables/sentences)) %>%
lm(flesch_ease_de ~ news_name*wordnum_utterance + news_name*sylnum_utterance, data = .) %>%
tidy() %>%
mutate(term = str_replace(term, "news_name", "")) %>%
arrange(-estimate)## # A tibble: 18 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 68.7 0.210 327. 0
## 2 romane 23.7 2.45 9.67 5.18e-22
## 3 stern_g 10.2 0.539 18.9 4.70e-78
## 4 wordnum_utterance 5.49 0.0420 131. 0
## 5 welt_co 4.29 0.250 17.1 1.46e-64
## 6 spiegel 1.99 0.284 7.02 2.48e-12
## 7 romane:sylnum_utterance 0.558 0.409 1.37 1.72e- 1
## 8 focus_c:wordnum_utterance 0.389 0.918 0.424 6.72e- 1
## 9 spiegel:wordnum_utterance 0.211 0.0561 3.76 1.71e- 4
## 10 welt_co:sylnum_utterance -0.0184 0.0253 -0.728 4.67e- 1
## 11 focus_c:sylnum_utterance -0.131 0.395 -0.333 7.39e- 1
## 12 spiegel:sylnum_utterance -0.182 0.0261 -6.98 3.20e-12
## 13 stern_g:sylnum_utterance -0.219 0.0563 -3.90 9.88e- 5
## 14 stern_g:wordnum_utterance -0.220 0.114 -1.92 5.44e- 2
## 15 welt_co:wordnum_utterance -0.227 0.0531 -4.28 1.88e- 5
## 16 romane:wordnum_utterance -2.22 0.668 -3.33 8.75e- 4
## 17 focus_c -2.45 4.03 -0.607 5.44e- 1
## 18 sylnum_utterance -3.39 0.0195 -174. 0Nur statistisch signifikante Interaktionen:
lesbarkeitsindex %>%
mutate(wordnum_utterance = (words/sentences),
sylnum_utterance = (syllables/sentences)) %>%
lm(flesch_ease_de ~ news_name*wordnum_utterance + news_name*sylnum_utterance, data = .) %>%
tidy() %>%
mutate(term = str_replace(term, "news_name", "")) %>%
mutate(pval = case_when(
p.value < 0.05 ~ "significant",
TRUE ~ "---")) %>%
mutate(pval = ifelse(term == "(Intercept)", "xxx", pval)) %>%
filter(pval == "significant" | pval == "xxx") %>%
filter(str_detect(term, ":")) %>%
arrange(-estimate)## # A tibble: 5 x 6
## term estimate std.error statistic p.value pval
## <chr> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 spiegel:wordnum_utterance 0.211 0.0561 3.76 1.71e- 4 significant
## 2 spiegel:sylnum_utterance -0.182 0.0261 -6.98 3.20e-12 significant
## 3 stern_g:sylnum_utterance -0.219 0.0563 -3.90 9.88e- 5 significant
## 4 welt_co:wordnum_utterance -0.227 0.0531 -4.28 1.88e- 5 significant
## 5 romane:wordnum_utterance -2.22 0.668 -3.33 8.75e- 4 significantIn den Romanen sind die Wörter im Durchschnitt kürzer als in den Zeitungstexten (Spiegel …). “Tidy”-Version:
lesbarkeitsindex %>%
group_by(news_name) %>%
summarise(syl_per_wrd = mean(syllables/words),
sd_syl_per_wrd = sd(syllables/words))## # A tibble: 6 x 3
## news_name syl_per_wrd sd_syl_per_wrd
## <fct> <dbl> <dbl>
## 1 faz_cor 1.91 0.143
## 2 focus_c 1.93 0.0888
## 3 romane 1.47 0.0719
## 4 spiegel 1.89 0.116
## 5 stern_g 1.75 0.109
## 6 welt_co 1.86 0.135Die Anzahl der Silben pro Äußerung in den Romanen ist vergleichbar mit der in Zeitungstexten (z.B. Spiegel).
lesbarkeitsindex %>%
group_by(news_name) %>%
summarise(syl_per_utt = mean(syllables/sentences),
sd_syl_per_utt = sd(syllables/sentences))## # A tibble: 6 x 3
## news_name syl_per_utt sd_syl_per_utt
## <fct> <dbl> <dbl>
## 1 faz_cor 33.8 8.61
## 2 focus_c 33.3 5.88
## 3 romane 31.0 8.88
## 4 spiegel 30.6 5.91
## 5 stern_g 27.9 5.89
## 6 welt_co 30.4 8.74Die Romane haben durchschnittlich mehr Wörter pro Äußerung.
lesbarkeitsindex %>%
group_by(news_name) %>%
summarise(wrds_per_utt = mean(words/sentences),
sd_wrds_per_utt = sd(words/sentences))## # A tibble: 6 x 3
## news_name wrds_per_utt sd_wrds_per_utt
## <fct> <dbl> <dbl>
## 1 faz_cor 17.6 3.99
## 2 focus_c 17.2 2.53
## 3 romane 20.9 5.43
## 4 spiegel 16.2 2.75
## 5 stern_g 15.9 2.93
## 6 welt_co 16.2 4.37lesbarkeit = lesbarkeitsindex %>%
mutate(functiontype = case_when(
news_name == "romane" ~ "literatur",
news_name != "romane" ~ "zeitung",
TRUE ~ "other"
)) %>%
mutate(syl_per_wrd = (syllables/words),
wordnum_utterance = (words/sentences),
sylnum_utterance = (syllables/sentences))
lesbarkeit %>%
slice_sample(n = 30) %>%
select(-text) %>%
rmarkdown::paged_table()Die Romane haben kürzere Wörter als die Zeitungstexte (d.h. weniger Silben).
# set contrast back to default ("contr.treatment")
contrasts(lesbarkeitsindex$news_name) <- NULL
levels(lesbarkeitsindex$news_name)## [1] "faz_cor" "focus_c" "romane" "spiegel" "stern_g" "welt_co"contrasts(lesbarkeitsindex$news_name) <- contr.treatment(6, base = 3) # base = romane !
contrasts(lesbarkeitsindex$news_name) # take a look## 1 2 4 5 6
## faz_cor 1 0 0 0 0
## focus_c 0 1 0 0 0
## romane 0 0 0 0 0
## spiegel 0 0 1 0 0
## stern_g 0 0 0 1 0
## welt_co 0 0 0 0 1lesbarkeit %>%
lm(syl_per_wrd ~ news_name, data = .) %>%
summary()##
## Call:
## lm(formula = syl_per_wrd ~ news_name, data = .)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.73696 -0.07736 0.00306 0.07656 0.56661
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.910836 0.003187 599.592 < 2e-16 ***
## news_namefocus_c 0.016906 0.033068 0.511 0.609
## news_nameromane -0.438972 0.036937 -11.884 < 2e-16 ***
## news_namespiegel -0.023832 0.003878 -6.145 8.39e-10 ***
## news_namestern_g -0.163793 0.006862 -23.869 < 2e-16 ***
## news_namewelt_co -0.048874 0.004045 -12.081 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.1275 on 8004 degrees of freedom
## Multiple R-squared: 0.08559, Adjusted R-squared: 0.08502
## F-statistic: 149.8 on 5 and 8004 DF, p-value: < 2.2e-16Die Romane haben durchschnittlich mehr Wörter pro Äußerung.
contrasts(lesbarkeitsindex$news_name) <- NULL
levels(lesbarkeitsindex$news_name)## [1] "faz_cor" "focus_c" "romane" "spiegel" "stern_g" "welt_co"contrasts(lesbarkeitsindex$news_name) <- contr.treatment(6, base = 3) # base = romane !
contrasts(lesbarkeitsindex$news_name) # take a look## 1 2 4 5 6
## faz_cor 1 0 0 0 0
## focus_c 0 1 0 0 0
## romane 0 0 0 0 0
## spiegel 0 0 1 0 0
## stern_g 0 0 0 1 0
## welt_co 0 0 0 0 1lesbarkeit %>%
lm(wordnum_utterance ~ news_name, data = .) %>%
summary()##
## Call:
## lm(formula = wordnum_utterance ~ news_name, data = .)
##
## Residuals:
## Min 1Q Median 3Q Max
## -10.245 -2.098 -0.345 1.811 66.755
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 17.58859 0.09039 194.575 < 2e-16 ***
## news_namefocus_c -0.37430 0.93796 -0.399 0.68986
## news_nameromane 3.35050 1.04770 3.198 0.00139 **
## news_namespiegel -1.39927 0.11001 -12.720 < 2e-16 ***
## news_namestern_g -1.67816 0.19464 -8.622 < 2e-16 ***
## news_namewelt_co -1.34374 0.11475 -11.710 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.616 on 8004 degrees of freedom
## Multiple R-squared: 0.02589, Adjusted R-squared: 0.02528
## F-statistic: 42.55 on 5 and 8004 DF, p-value: < 2.2e-16Noch deutlicher sichtbar in der Gegenüberstellung (Literatur vs. Zeitung):
lesbarkeit %>%
lm(wordnum_utterance ~ functiontype, data = .) %>%
summary()##
## Call:
## lm(formula = wordnum_utterance ~ functiontype, data = .)
##
## Residuals:
## Min 1Q Median 3Q Max
## -10.474 -2.239 -0.258 1.602 66.526
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 20.939 1.056 19.826 < 2e-16 ***
## functiontypezeitung -4.465 1.057 -4.225 2.42e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.659 on 8008 degrees of freedom
## Multiple R-squared: 0.002224, Adjusted R-squared: 0.002099
## F-statistic: 17.85 on 1 and 8008 DF, p-value: 2.42e-05Längere Wörter (mehr Silben pro Wort) in Zeitungen als in Romanen.
lesbarkeit %>%
lm(syl_per_wrd ~ functiontype, data = .) %>%
summary()##
## Call:
## lm(formula = syl_per_wrd ~ functiontype, data = .)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.75095 -0.08350 0.00680 0.08442 0.55262
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.47186 0.03821 38.52 <2e-16 ***
## functiontypezeitung 0.40409 0.03824 10.57 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.1324 on 8008 degrees of freedom
## Multiple R-squared: 0.01376, Adjusted R-squared: 0.01363
## F-statistic: 111.7 on 1 and 8008 DF, p-value: < 2.2e-16Aber die Anzahl der Silben pro Äußerung in den Romanen und Zeitungstexten unterscheidet sich nicht wesentlich (p = 0,979).
lesbarkeit %>%
lm(sylnum_utterance ~ functiontype, data = .) %>%
summary()##
## Call:
## lm(formula = sylnum_utterance ~ functiontype, data = .)
##
## Residuals:
## Min 1Q Median 3Q Max
## -24.274 -4.649 -0.522 3.946 125.976
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 30.96610 2.20905 14.018 <2e-16 ***
## functiontypezeitung 0.05815 2.21071 0.026 0.979
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 7.652 on 8008 degrees of freedom
## Multiple R-squared: 8.64e-08, Adjusted R-squared: -0.0001248
## F-statistic: 0.0006919 on 1 and 8008 DF, p-value: 0.97916.11 Flesch-Kincade Grade Level (USA, GB)
https://paldhous.github.io/NICAR/2019/r-text-analysis.html
The code below uses the quanteda functions ntoken, nsentence and nsyllable to count the words, sentences, and syllables in each addresss. Then it uses those values to calculate the Flesch-Kincaid reading grade level, a widely used measure of linguistic complexity.
sou = read_csv("data/sou.csv")# word, sentence, and syllable counts, plus reading scores
sou = sou %>%
mutate(syllables = nsyllable(text),
sentences = nsentence(text),
words = ntoken(text, remove_punct = TRUE),
fk_grade = 0.39*(words/sentences) + 11.8*(syllables/words) - 15.59) %>%
arrange(date)The following chart shows how the reading grade level of State of the Union addresses has declined over the years. The points on the chart are colored by party, and scaled by the length of the address in words.
# color palette for parties
party_pal <- c("#1482EE","#228B22","#E9967A","#686868","#FF3300","#EEC900")
# reading score chart
ggplot(sou, aes(x = date, y = fk_grade, color = party, size = words)) +
geom_point(alpha = 0.5) +
geom_smooth(se = FALSE, color = "black", method = "lm", size = 0.5, linetype = "dotted") +
scale_size_area(max_size = 10, guide = "none") +
scale_color_manual(values = party_pal, name = "", breaks = c("Democratic","Republican","Whig","Democratic-Republican","Federalist","None")) +
scale_y_continuous(limits = c(4,27), breaks = c(5,10,15,20,25)) +
theme_minimal(base_size = 18) +
xlab("") +
ylab("Reading level") +
guides(col = guide_legend(ncol = 2, override.aes = list(size = 4))) +
theme(legend.position = c(0.4,0.22),
legend.text = element_text(color="#909090", size = 16),
panel.grid.minor = element_blank())
library(plotly)
# color palette for parties
party_pal <- c("#1482EE","#228B22","#E9967A","#686868","#FF3300","#EEC900")
# reading score chart
u <- ggplot(sou, aes(x = date, y = fk_grade, color = party, size = words)) +
geom_point(alpha = 0.5) +
geom_smooth(se = FALSE, color = "black", method = "lm", size = 0.5, linetype = "dotted") +
scale_size_area(max_size = 10, guide = "none") +
scale_color_manual(values = party_pal, name = "", breaks = c("Democratic","Republican","Whig","Democratic-Republican","Federalist","None")) +
scale_y_continuous(limits = c(4,27), breaks = c(5,10,15,20,25)) +
theme_minimal(base_size = 18) +
xlab("") +
ylab("Reading level") +
guides(col = guide_legend(ncol = 2, override.aes = list(size = 4))) +
theme(legend.position = c(0.4,0.22),
legend.text = element_text(color="#909090", size = 16),
panel.grid.minor = element_blank())
ggplotly(u, height = 500, width = 1000)16.12 Wiener Sachtextformel
https://de.wikipedia.org/wiki/Lesbarkeitsindex
Die Wiener Sachtextformel dient zur Berechnung der Lesbarkeit deutschsprachiger Texte. Sie gibt an, für welche Schulstufe ein Sachtext geeignet ist. Die Skala beginnt bei Schulstufe 4 und endet bei 15, wobei ab der Stufe 12 eher von Schwierigkeitsstufen als von Schulstufen gesprochen werden sollte. Ein Wert von 4 steht demnach für sehr leichten Text, dagegen bezeichnet 15 einen sehr schwierigen Text.
Die Formel wurde aufgestellt von Richard Bamberger und Erich Vanecek.
MS ist der Prozentanteil der Wörter mit drei oder mehr Silben, SL ist die mittlere Satzlänge (Anzahl Wörter), IW ist der Prozentanteil der Wörter mit mehr als sechs Buchstaben, ES ist der Prozentanteil der einsilbigen Wörter.
Die erste Wiener Sachtextformel WSTF1 = 0.1935 * MS + 0.1672 * SL + 0.1297 * IW - 0.0327 * ES - 0.875 Die zweite Wiener Sachtextformel WSTF2 = 0.2007 * MS + 0.1682 * SL + 0.1373 * IW - 2.7 Die dritte Wiener Sachtextformel WSTF3 = 0.2963 * MS + 0.1905 * SL - 1.114 Die vierte Wiener Sachtextformel („im Hinblick auf die Jahrgangsstufe“) WSTF4 = 0.2744 * MS + 0.2656 * SL - 1.69
# Das Beispiel mit den Entchen liefert mit der ersten WSTF einen Index von 3.8:
satz="Alle meine Entchen schwimmen auf dem See, Köpfchen unters Wasser, Schwänzchen in die Höh."
WSTF1 = 0.1935 * 0 + 0.1672 * 14 + 0.1297 * 29 - 0.0327 * 43 - 0.875In unserem Korpus:
lesbarkeitsindex %>%
filter(news_name == "faz_cor") %>%
add_count(news_name) %>%
unnest_tokens(word, text) %>%
mutate(ms = ifelse(nsyllable(word) > 2, 1, 0), # Wort mit mehr als 2 Silben
iw = ifelse(nchar(word) > 5, 1, 0), # Wort mit mehr als 5 Buchstaben
es = ifelse(nsyllable(word) < 2, 1, 0)) %>% # Wort mit einer Silbe
drop_na() %>%
group_by(news_name) %>%
summarise(MS = sum(100*ms/(words*n)), # MS: Prozentanteil der Wörter mit 3 oder mehr Silben
SL = mean(words/sentences), # SL: mittlere Satzlänge (Anzahl Wörter)
IW = sum(100*iw/(words*n)), # IW: Prozentanteil der Wörter mit mehr als 6 Buchstaben
ES = sum(100*es/(words*n))) %>% # ES: Prozentanteil der einsilbigen Wörter
mutate(WSTF1 = 0.1935 * MS + 0.1672 * SL + 0.1297 * IW - 0.0327 * ES - 0.875,
WSTF2 = 0.2007 * MS + 0.1682 * SL + 0.1373 * IW - 2.7,
WSTF3 = 0.2963 * MS + 0.1905 * SL - 1.114,
WSTF4 = 0.2744 * MS + 0.2656 * SL - 1.69)## # A tibble: 1 x 9
## news_name MS SL IW ES WSTF1 WSTF2 WSTF3 WSTF4
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 faz_cor 25.4 17.8 43.8 47.1 11.1 11.4 9.80 10.0lesbarkeitsindex %>%
filter(news_name == "spiegel") %>%
add_count(news_name) %>%
unnest_tokens(word, text) %>%
mutate(ms = ifelse(nsyllable(word) > 2, 1, 0), # Wort mit mehr als 2 Silben
iw = ifelse(nchar(word) > 5, 1, 0), # Wort mit mehr als 5 Buchstaben
es = ifelse(nsyllable(word) < 2, 1, 0)) %>% # Wort mit einer Silbe
drop_na() %>%
group_by(news_name) %>%
summarise(MS = sum(100*ms/(words*n)), # MS: Prozentanteil der Wörter mit 3 oder mehr Silben
SL = mean(words/sentences), # SL: mittlere Satzlänge (Anzahl Wörter)
IW = sum(100*iw/(words*n)), # IW: Prozentanteil der Wörter mit mehr als 6 Buchstaben
ES = sum(100*es/(words*n))) %>% # ES: Prozentanteil der einsilbigen Wörter
mutate(WSTF1 = 0.1935 * MS + 0.1672 * SL + 0.1297 * IW - 0.0327 * ES - 0.875,
WSTF2 = 0.2007 * MS + 0.1682 * SL + 0.1373 * IW - 2.7,
WSTF3 = 0.2963 * MS + 0.1905 * SL - 1.114,
WSTF4 = 0.2744 * MS + 0.2656 * SL - 1.69)## # A tibble: 1 x 9
## news_name MS SL IW ES WSTF1 WSTF2 WSTF3 WSTF4
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 spiegel 24.8 16.3 44.2 47.3 10.8 11.1 9.33 9.43lesbarkeitsindex %>%
filter(news_name == "welt_co") %>%
add_count(news_name) %>%
unnest_tokens(word, text) %>%
mutate(ms = ifelse(nsyllable(word) > 2, 1, 0), # Wort mit mehr als 2 Silben
iw = ifelse(nchar(word) > 5, 1, 0), # Wort mit mehr als 5 Buchstaben
es = ifelse(nsyllable(word) < 2, 1, 0)) %>% # Wort mit einer Silbe
drop_na() %>%
group_by(news_name) %>%
summarise(MS = sum(100*ms/(words*n)), # MS: Prozentanteil der Wörter mit 3 oder mehr Silben
SL = mean(words/sentences), # SL: mittlere Satzlänge (Anzahl Wörter)
IW = sum(100*iw/(words*n)), # IW: Prozentanteil der Wörter mit mehr als 6 Buchstaben
ES = sum(100*es/(words*n))) %>% # ES: Prozentanteil der einsilbigen Wörter
mutate(WSTF1 = 0.1935 * MS + 0.1672 * SL + 0.1297 * IW - 0.0327 * ES - 0.875,
WSTF2 = 0.2007 * MS + 0.1682 * SL + 0.1373 * IW - 2.7,
WSTF3 = 0.2963 * MS + 0.1905 * SL - 1.114,
WSTF4 = 0.2744 * MS + 0.2656 * SL - 1.69)## # A tibble: 1 x 9
## news_name MS SL IW ES WSTF1 WSTF2 WSTF3 WSTF4
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 welt_co 24.0 16.4 43.1 48.6 10.5 10.8 9.11 9.24lesbarkeitsindex %>%
filter(news_name == "stern_g") %>%
add_count(news_name) %>%
unnest_tokens(word, text) %>%
mutate(ms = ifelse(nsyllable(word) > 2, 1, 0), # Wort mit mehr als 2 Silben
iw = ifelse(nchar(word) > 5, 1, 0), # Wort mit mehr als 5 Buchstaben
es = ifelse(nsyllable(word) < 2, 1, 0)) %>% # Wort mit einer Silbe
drop_na() %>%
group_by(news_name) %>%
summarise(MS = sum(100*ms/(words*n)), # MS: Prozentanteil der Wörter mit 3 oder mehr Silben
SL = mean(words/sentences), # SL: mittlere Satzlänge (Anzahl Wörter)
IW = sum(100*iw/(words*n)), # IW: Prozentanteil der Wörter mit mehr als 6 Buchstaben
ES = sum(100*es/(words*n))) %>% # ES: Prozentanteil der einsilbigen Wörter
mutate(WSTF1 = 0.1935 * MS + 0.1672 * SL + 0.1297 * IW - 0.0327 * ES - 0.875,
WSTF2 = 0.2007 * MS + 0.1682 * SL + 0.1373 * IW - 2.7,
WSTF3 = 0.2963 * MS + 0.1905 * SL - 1.114,
WSTF4 = 0.2744 * MS + 0.2656 * SL - 1.69)## # A tibble: 1 x 9
## news_name MS SL IW ES WSTF1 WSTF2 WSTF3 WSTF4
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 stern_g 20.3 16.0 39.8 49.1 9.28 9.53 7.95 8.13lesbarkeitsindex %>%
filter(news_name == "focus_c") %>%
add_count(news_name) %>%
unnest_tokens(word, text) %>%
mutate(ms = ifelse(nsyllable(word) > 2, 1, 0), # Wort mit mehr als 2 Silben
iw = ifelse(nchar(word) > 5, 1, 0), # Wort mit mehr als 5 Buchstaben
es = ifelse(nsyllable(word) < 2, 1, 0)) %>% # Wort mit einer Silbe
drop_na() %>%
group_by(news_name) %>%
summarise(MS = sum(100*ms/(words*n)), # MS: Prozentanteil der Wörter mit 3 oder mehr Silben
SL = mean(words/sentences), # SL: mittlere Satzlänge (Anzahl Wörter)
IW = sum(100*iw/(words*n)), # IW: Prozentanteil der Wörter mit mehr als 6 Buchstaben
ES = sum(100*es/(words*n))) %>% # ES: Prozentanteil der einsilbigen Wörter
mutate(WSTF1 = 0.1935 * MS + 0.1672 * SL + 0.1297 * IW - 0.0327 * ES - 0.875,
WSTF2 = 0.2007 * MS + 0.1682 * SL + 0.1373 * IW - 2.7,
WSTF3 = 0.2963 * MS + 0.1905 * SL - 1.114,
WSTF4 = 0.2744 * MS + 0.2656 * SL - 1.69)## # A tibble: 1 x 9
## news_name MS SL IW ES WSTF1 WSTF2 WSTF3 WSTF4
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 focus_c 26.2 16.9 45.2 46.0 11.4 11.6 9.86 9.98lesbarkeitsindex %>%
filter(news_name == "romane") %>%
add_count(news_name) %>%
unnest_tokens(word, text) %>%
mutate(ms = ifelse(nsyllable(word) > 2, 1, 0), # Wort mit mehr als 2 Silben
iw = ifelse(nchar(word) > 5, 1, 0), # Wort mit mehr als 5 Buchstaben
es = ifelse(nsyllable(word) < 2, 1, 0)) %>% # Wort mit einer Silbe
drop_na() %>%
group_by(news_name) %>%
summarise(MS = sum(100*ms/(words*n)), # MS: Prozentanteil der Wörter mit 3 oder mehr Silben
SL = mean(words/sentences), # SL: mittlere Satzlänge (Anzahl Wörter)
IW = sum(100*iw/(words*n)), # IW: Prozentanteil der Wörter mit mehr als 6 Buchstaben
ES = sum(100*es/(words*n))) %>% # ES: Prozentanteil der einsilbigen Wörter
mutate(WSTF1 = 0.1935 * MS + 0.1672 * SL + 0.1297 * IW - 0.0327 * ES - 0.875,
WSTF2 = 0.2007 * MS + 0.1682 * SL + 0.1373 * IW - 2.7,
WSTF3 = 0.2963 * MS + 0.1905 * SL - 1.114,
WSTF4 = 0.2744 * MS + 0.2656 * SL - 1.69)## # A tibble: 1 x 9
## news_name MS SL IW ES WSTF1 WSTF2 WSTF3 WSTF4
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 romane 13.3 19.0 31.1 51.9 7.21 7.44 6.45 7.01wstf1_idx = lesbarkeitsindex_romane %>%
unnest_tokens(word, text) %>%
mutate(ms = ifelse(nsyllable(word) > 2, 1, 0),
iw = ifelse(nchar(word) > 5, 1, 0),
es = ifelse(nsyllable(word) < 2, 1, 0)) %>%
drop_na() %>%
group_by(book_name) %>%
summarise(MS = sum(100*ms/words),
SL = mean(words/sentences),
IW = sum(100*iw/words),
ES = sum(100*es/words))
wstf1_idx %>% rmarkdown::paged_table()lesbarkeitsindex_romane %>%
# filter(str_detect(book_name, "Der Prozess")) %>%
unnest_tokens(word, text) %>%
mutate(ms = ifelse(nsyllable(word) > 2, 1, 0),
iw = ifelse(nchar(word) > 5, 1, 0),
es = ifelse(nsyllable(word) < 2, 1, 0)) %>%
drop_na() %>%
group_by(book_name) %>%
summarise(MS = sum(100*ms/words),
SL = mean(words/sentences),
IW = sum(100*iw/words),
ES = sum(100*es/words)) %>%
mutate(WSTF1 = 0.1935 * MS + 0.1672 * SL + 0.1297 * IW - 0.0327 * ES - 0.875,
WSTF2 = 0.2007 * MS + 0.1682 * SL + 0.1373 * IW - 2.7,
WSTF3 = 0.2963 * MS + 0.1905 * SL - 1.114,
WSTF4 = 0.2744 * MS + 0.2656 * SL - 1.69) %>%
rmarkdown::paged_table()