Kapitel 18 Rolling Stones auf Twitter
18.2 Programme
library(tidyverse)
library(tidytext)
library(rtweet)
library(lubridate)
library(plotly)
library(leaflet)
library(glue)
library(htmlwidgets)
library(DT)
library(gganimate)
library(gifski)
library(ggthemes)Das rtweet-Programm ermöglicht den Zugang zu Twitter-Texten und Twitter-Usern. Dazu benötigt man einen Twitter-Account, außerdem muss man eine Twitter-App einstellen. Das erfordert eine Telefonnummer zur Verifizierung. Genauere Angaben sind auf verschiedenen Internetseiten zu finden, z.B. Twitter-App setup.
Im rtweet package stehen mehrere Funktionen zur Verfügung, um tweets vom Twitter-API zu erfassen:
search_tweets()– erfasst Tweets der letzten 6-9 Tage, die einem vom User festgelegten Stichwort (query) entsprechen.stream_tweets()– erfasst Tweets aus dem live Datenstromget_timelines()– erfasst Tweets von ausgewählten Twitter-Nutzern.
Die Tweets (d.h. der Text und zahlreiche Metadaten) werden in der Form eines Datensatzes (data.frame bzw. tibble) organisiert und können auch auf der Festplatte gespeichert werden.
18.3 Datenstrom holen
Eine Möglichkeit ist die Tweets live einzufangen, und zwar mit der Funktion stream_tweets().
library(tidyverse)
library(rtweet)
## Stream keywords used to filter tweets
q <- "RollingStones"
## Stream for 30 minutes
streamtime <- 30 * 60
## Filename to save json data (backup)
filename <- "data/rollingstones.json"
## Stream tweets
rt_rollingstones <- stream_tweets(q = q, timeout = streamtime, file_name = filename)Laden der gespeicherten Daten von Disk:
library(jsonlite)
fromJSON("data/rollingstones.json")18.4 Tweets holen
Typischerweise laden wir die Tweets der letzten sechs bis neun Tage herunter, indem wir in die Funktion search_tweets() ein Schlagwort (q) eingeben, das unserem Ziel entspricht.
Die Anzahl der Tweets in unserer Recherche ist begrenzt (n = 18000 Tweets).
Will man zwei oder mehrere miteinander auftretende Wörter (etwa Kollokationen) in einer Recherche verwenden, sollte man ein Pluszeichen zwischen die Wörter setzen, z.B. q = "Charlie+Watts".
Die Argumente q und n sind notwendig zur Recherche.
Die Suchfunktion hat mehrere optionale Argumente, z.B. die Sprache lang, Herausfiltern von Retweets mit Hilfe des Schalters include_rts = FALSE u.a.
Tweets in deutscher Sprache zum Thema RollingStones:
library(tidyverse)
library(rtweet)
q <- "RollingStones"
tweets_rollingstones_de <- search_tweets(q = q,
n = 18000,
token = bearer_token(),
include_rts = FALSE,
`-filter` = "replies",
lang = "de")
tweets_rollingstones_deEin Retweet bedeutet, dass ein Nutzer den Tweet einer anderen Person teilt, so dass auch die Follower den Beitrag sehen können. Tweets und Retweets kann man separat aus dem Datensatz abrufen.
Tweets in slowenischer Sprache zum Thema “RollingStones”:
q <- "RollingStones"
tweets_rollingstones_sl <- search_tweets(q = q,
n = 18000,
token = bearer_token(),
include_rts = FALSE,
`-filter` = "replies",
lang = "sl")
tweets_rollingstones_slTweets in englischer Sprache zum Thema “RollingStones”:
q <- "RollingStones"
tweets_rollingstones_en <- search_tweets(q = q,
n = 18000,
token = bearer_token(),
include_rts = FALSE,
`-filter` = "replies",
lang = "en")
tweets_rollingstones_en18.5 Datensatz erstellen
Die drei sprachspezifischen Tabellen wollen wir in einer gemeinsamen Tabelle speichern. Die Tabellenspalte “lang” enthält eine Angabe darüber, welche Sprache in den einzelnen Tweets verwendet wurden.
tweets_rollingstones <- bind_rows(tweets_rollingstones_sl,
tweets_rollingstones_de,
tweets_rollingstones_en)18.6 Datensatz speichern
Die gemeinsame Tabelle können wir nun auf Festplatte speichern. Die Datei mit der Endung rds kann nur vom Programm R gelesen werden. Eine Excel-Datei kann man beispielsweise mit dem writexl-Packet schreiben.
library(writexl)
write_xlsx(tweets_rollingstones, "data/tweets_rollingstones.xlsx")
write_rds(tweets_rollingstones, "data/tweets_rollingstones.rds")18.7 Datensatz laden
Am nächsten Tag fahren wir mit unsere Analyse fort und laden unseren Datensatz.
tweets_rollingstones <- read_rds("data/tweets_rollingstones.rds")18.8 Verfasser der Tweets
Unter den Twitternutzern, die Tweets anlässlich des Todes von Charlie Watts, dem Drummer der Rolling Stones, sind einige uns bekannte Namen zu finden, z.B. der slowenische Radiosender “Val202”. Die Schreiber der Tweets findet man in der Tabellenspalte screen_name.
tweets_rollingstones %>%
filter(str_detect(screen_name, "Val202")) %>%
rmarkdown::paged_table()tweets_rollingstones_sl <- subset(tweets_rollingstones, lang == "sl")
## plot multiple time series by first grouping the data by screen name
tweets_rollingstones_sl %>%
dplyr::group_by(screen_name) %>%
ts_plot() +
ggplot2::labs(
title = "Tweets after the death of Charlie Watts, drummer",
subtitle = "Tweets collected, parsed, and plotted using `rtweet`"
)
Tweets der deutschen Zeitung “FAZ” (Frankfurter Allgemeine Zeitung):
tweets_rollingstones %>%
filter(str_detect(screen_name, "faznet")) %>%
rmarkdown::paged_table()Der Tagesspiegel:
tweets_rollingstones %>%
filter(str_detect(screen_name, "Tagesspiegel")) %>%
rmarkdown::paged_table()tweets_rollingstones_de <- subset(tweets_rollingstones, lang == "de")
## plot multiple time series by first grouping the data by screen name
tweets_rollingstones_de %>%
group_by(created_at, screen_name) %>%
count(screen_name, sort = TRUE) %>%
ungroup() %>%
mutate(screen_name = fct_lump(screen_name, 9)) %>%
dplyr::group_by(screen_name) %>%
ts_plot() +
ggplot2::labs(y = "log10(# Tweets)",
title = "Tweets after the death of Charlie Watts, drummer",
subtitle = "Tweets collected, parsed, and plotted using `rtweet`"
) +
scale_y_log10()
tweets_rollingstones_en <- subset(tweets_rollingstones, lang == "en")
## plot multiple time series by first grouping the data by screen name
tweets_rollingstones_en %>%
group_by(created_at, screen_name) %>%
count(screen_name, sort = TRUE) %>%
ungroup() %>%
mutate(screen_name = fct_lump(screen_name, 9)) %>%
dplyr::group_by(screen_name) %>%
ts_plot() +
ggplot2::labs(y = "log10(# Tweets)",
title = "Tweets after the death of Charlie Watts, drummer",
subtitle = "Tweets collected, parsed, and plotted using `rtweet`"
) +
scale_y_log10()
18.9 Timeplot
Die Anzahl der veröffentlichten Tweets zum Thema können wir in einem Diagramm chronologisch darstellen. Im folgenden Diagramm bildet die Anzahl der Tweets innerhalb von drei Stunden jeweils einen Datenpunkt. Zunächst bilden wir die englischsprachigen Tweets ab.
## subset dataframe
tweets_rollingstones_en = subset(tweets_rollingstones, lang == "en")
## plot time series of tweets
p1 <- ts_plot(tweets_rollingstones_en, "3 hours", color = "red") +
ggplot2::theme_minimal() +
ggplot2::theme(plot.title = ggplot2::element_text(face = "bold")) +
ggplot2::labs(
x = NULL, y = NULL,
title = "Frequency of #rollingstones Twitter statuses from past 9 days",
subtitle = "Twitter status (tweet) counts aggregated using three-hour intervals",
caption = "\nSource: Data collected from Twitter's REST API via rtweet")
p1
Ein interaktives Diagramm können wir mit plotly erstellen.
library(plotly)
ggplotly(p1) %>% layout()Die deutschsprachigen Tweets:
## subset dataframe
tweets_rollingstones_de = subset(tweets_rollingstones, lang == "de")
## plot time series of tweets
p2 <- ts_plot(tweets_rollingstones_de,
"3 hours",
color = "darkgreen") +
ggplot2::theme_minimal() +
ggplot2::theme(plot.title = ggplot2::element_text(face = "bold")) +
ggplot2::labs(
x = NULL, y = NULL,
title = "Frequency of #rollingstones Twitter statuses from past 9 days",
subtitle = "Twitter status (tweet) counts aggregated using three-hour intervals",
caption = "\nSource: Data collected from Twitter's REST API via rtweet")
p2
Ein interaktives Diagramm können wir wiederum mit plotly erstellen.
library(plotly)
ggplotly(p2) %>% layout()In beiden Fällen flacht die Verlaufskurve schnell ab.
18.10 User-Informationen
Aus unserem Datensatz können wir mit users_data() auch Informationen über die Twitter-Nutzer herausholen, die einen Tweet zum Thema #RollingStones (in den vergangenen 6-9 Tagen) verfasst hat, z.B. wie viele Follower sie haben, wie viele Freunde, wie viele Tweets sie verfasst haben, Beschreibungen über sich selbst u.a.
tweets_rollingstones %>%
users_data() %>%
rmarkdown::paged_table()Ähnliche (obwohl weniger nützliche) Funktionen sind users_with_tweets() und tweets_with_users().
users_with_tweets(tweets_rollingstones)
tweets_with_users(tweets_rollingstones)18.11 Geographische Verteilung
Aus welchen Ländern stammen die englischsprachigen Tweets?
In der Tabellenspalte country finden wir leider in den meisten Fällen keine Angabe (NA), aber die am häufigsten angezeigten Staaten sind die USA, Großbritannien, Ausralien, Kanada und Irland, in denen Englisch Amtssprache ist.
tweets_rollingstones_en %>%
count(country, sort = TRUE)## # A tibble: 48 x 2
## country n
## <chr> <int>
## 1 <NA> 17024
## 2 United States 393
## 3 United Kingdom 153
## 4 Australia 69
## 5 Canada 53
## 6 Ireland 20
## 7 France 19
## 8 Argentina 15
## 9 Brazil 15
## 10 Italy 15
## # ... with 38 more rowsWählen wir die Tabellenspalte location als Ausgangspunkt, dann erhalten wir recht chaotische Sammlung von Stadt-, Staats- und anderen geographischen Bezeichnungen, die man nach vorheriger Bereinigung nutzen könnte, z.B. kartographisch.
tweets_rollingstones_en %>%
count(location, sort = TRUE)## # A tibble: 6,264 x 2
## location n
## <chr> <int>
## 1 "" 4682
## 2 "United States" 155
## 3 "London, England" 130
## 4 "London" 126
## 5 "Los Angeles, CA" 109
## 6 "United Kingdom" 106
## 7 "Canada" 101
## 8 "Chicago, IL" 95
## 9 "New York, NY" 91
## 10 "UK" 75
## # ... with 6,254 more rowsFür eine graphische Darstellung wählen wir an dieser Stelle die (unkomplizierte) country-Spalte.
library(lubridate)
p3 <- tweets_rollingstones_en %>%
select(created_at, country) %>%
mutate(date = lubridate::as_date(created_at)) %>%
group_by(date, country) %>%
count(country, sort = TRUE) %>%
drop_na() %>%
ungroup() %>%
mutate(country = fct_lump(country, 9)) %>% # nur 9+1 Staaten
ggplot(aes(date, n, fill = country)) +
geom_col()
p3
library(plotly)
ggplotly(p3) %>% layout()Die graphische Darstellung für die deutschen Tweets nach Staaten:
p4 <- tweets_rollingstones_de %>%
select(created_at, country) %>%
mutate(date = lubridate::as_date(created_at)) %>%
group_by(date, country) %>%
count(country, sort = TRUE) %>%
drop_na() %>%
ungroup() %>%
mutate(country = fct_lump(country, 9)) %>%
ggplot(aes(date, n, fill = country)) +
geom_col()
p4
library(plotly)
ggplotly(p4) %>% layout()library(ggthemes)
m1 <- tweets_rollingstones %>%
unnest(geo_coords) %>%
unnest(coords_coords) %>%
separate(geo_coords, into = c("latitude","longit"),
sep = ";", remove = FALSE, extra = "merge") %>%
separate(coords_coords, into = c("longitude","latit"),
sep = ";", remove = FALSE, extra = "merge") %>%
mutate(latitude = parse_number(latitude),
longitude = parse_number(longitude)) %>%
select(country, latitude, longitude,
screen_name, status_id, location, text) %>%
filter(latitude != "" | longitude != "") %>%
distinct(status_id, .keep_all = TRUE) %>%
ggplot(aes(longitude, latitude, color = country)) +
borders() +
geom_point() +
theme_map() +
theme(legend.position = "bottom") +
labs(title = "Tweets around the World after Death of Charlie Watts",
color = "Country")
m1
Ein interaktives Diagramm können wir wiederum mit plotly erstellen.
library(plotly)
ggplotly(m1) %>% layout()Es gibt mehrere Datensätze, in denen die geographische Lage von Städten (also Längen- und Breitengrad) gespeichert ist. Das rtweet-Paket verfügt über einen kleineren Datensatz, erreichbar durch:
rtweet:::citycoords %>% rmarkdown::paged_table()Einen wesentlich umfangreicheren Datensatz findet man auf der Webseite von simplempas, neben den Angaben zur geographischen Lage und Staatszugehörigkeit auch die Einwohnerzahl.
world_cities <- read_csv("data/worldcities.csv")
world_cities <- world_cities %>%
select(city_ascii, country, lat, lng) %>%
rename(city = city_ascii, state_country = country)
world_cities %>% rmarkdown::paged_table()Die letztere Datensammlung fügen wir mit der Funktion left_join() unserem Twitter-Datensatz hinzu.
Im Twitter-Datensatz nehmen wir außerdem mehrere Korrekturen vor, und zwar mit den tidyverse-Funktionen separate() zur Trennung von Tabellenspalten, str_replace() zum Austausch von Angaben in den Tabellenspalten, str_to_sentence() zur Vereinheitlichung der Schreibweise sowie ifelse() und str_detect(), um Bezeichnungen unter passenden Bedingungen in einer Tabellenspalte ausfindig zu machen und zu ersetzen.
tweets_rollingstones_cities <- tweets_rollingstones %>%
separate(location,
into = c("city", "state_country"),
extra = "merge", fill = "right",
sep = ", ", remove = FALSE) %>%
separate(location,
into = c("city", "state_country"),
extra = "merge", fill = "right",
sep = " ", remove = FALSE) %>%
mutate(state_country = str_replace(state_country, "- ", "")) %>%
mutate(state_country = str_replace(state_country, "\\| ", "")) %>%
mutate(city = str_replace(city, ",", "")) %>%
mutate(city = str_to_sentence(city)) %>%
mutate(state_country = str_to_sentence(state_country)) %>%
mutate(state_country = ifelse(
country == "United States", "United States", state_country)) %>%
mutate(state_country = ifelse(
country == "United Kingdom", "United Kingdom", state_country)) %>%
mutate(state_country = ifelse(
str_detect(country, "Ireland"), "Ireland", state_country)) %>%
mutate(state_country = ifelse(
str_detect(country, "Australia"), "Australia", state_country)) %>%
mutate(state_country = str_replace(
state_country, "Western australia", "Australia")) %>%
mutate(state_country = str_replace(state_country,
"Slovenija", "Slovenia")) %>%
mutate(state_country = str_replace(state_country,
"Deutschland", "Germany")) %>%
mutate(state_country = str_replace(state_country,
"Österreich", "Austria")) %>%
mutate(state_country = str_replace(state_country,
"Schweiz", "Switzerland")) %>%
mutate(state_country = str_replace(state_country,
"England", "United Kingdom")) %>%
mutate(state_country = str_replace(state_country,
"am Main", "Germany")) %>%
mutate(city = str_replace(city, "Zürich", "Zurich")) %>%
mutate(city = str_replace(city, "Wien", "Vienna")) %>%
mutate(city = str_replace(city, "München", "Munich")) %>%
mutate(city = str_replace(city, "Köln", "Cologne")) %>%
mutate(city = str_replace(city, "Düsseldorf", "Dusseldorf")) %>%
mutate(city = str_replace(city, "Gießen", "Giessen")) %>%
mutate(state_country = ifelse(
city %in% c("Ljubljana","Maribor","Celje","Kranj", "Lucija"),
"Slovenia", state_country)) %>%
mutate(state_country = ifelse(city %in% c("Zurich","Basel"),
"Switzerland", state_country)) %>%
mutate(state_country = ifelse(city %in% c("Vienna","Graz"),
"Austria", state_country)) %>%
mutate(state_country = ifelse(city %in% c("Teheran"),
"Iran", state_country)) %>%
mutate(state_country = ifelse(city %in% c("Strasbourg"),
"France", state_country)) %>%
mutate(state_country = ifelse(
city %in% c("Berlin","Munich","Hamburg","Essen","Heilbronn",
"Dortmund","Cologne","Frankfurt","Hannover",
"Giessen","Konstanz","Rostock","Dusseldorf",
"Augsburg","Lohmar"),
"Germany", state_country)) %>%
mutate(state_country = ifelse(
str_detect(location, "United Kingdom"),
"United Kingdom", state_country)) %>%
mutate(city = ifelse(location == "United Kingdom",
"United Kingdom", city)) %>%
mutate(state_country = ifelse(
str_detect(location, "United States"),
"United States", state_country)) %>%
mutate(city = ifelse(location == "United States",
"" , city)) %>%
mutate(state_country = ifelse(
str_detect(location, "Germany"),
"Germany", state_country)) %>%
mutate(city = ifelse(location == "Germany",
"" , city)) %>%
mutate(city = ifelse(location == "Las Vegas, NV",
"Las Vegas" , city)) %>%
mutate(state_country = ifelse(location == "Las Vegas, NV",
"United States" , state_country)) %>%
mutate(city = ifelse(location == "Toronto/Las Vegas",
"Toronto" , city)) %>%
mutate(state_country = ifelse(location == "Toronto/Las Vegas",
"Canada" , state_country)) %>%
mutate(city = ifelse(location == "san francisco",
"San Francisco" , city)) %>%
mutate(state_country = ifelse(location == "san francisco",
"United States" , state_country))Der korrigierte und mit left_join() erweiterte Datensatz:
tweets_rollingstones_cities_joined <- tweets_rollingstones_cities %>%
left_join(world_cities, by = c("city", "state_country"))
tweets_rollingstones_cities_joined %>%
select(location, country, city, state_country, lat, lng) %>%
rmarkdown::paged_table()18.12 Speichern des erweiterten Datensatzes
write_rds(tweets_rollingstones_cities_joined,
"data/tweets_rollingstones_cities_joined.rds")
library(writexl)
write_xlsx(tweets_rollingstones_cities_joined,
"data/tweets_rollingstones_cities_joined.xlsx")18.13 Laden des erweiterten Datensatzes
Am nächsten Tag brauchen wir nicht all die oben durchgeführten Schritte noch einmal durchzuführen, sondern hier an dieser Stelle den relevanten Datensatz laden und weitermachen.
tweets_rollingstones_cities_joined <-
read_rds("data/tweets_rollingstones_cities_joined.rds")Eine einfache Weltkarte aus dem ggthemes-Paket, auf der die einzelnen Twitterorte als farbige Punkte eingetragen sind.
library(ggthemes)
m2 <- tweets_rollingstones_cities_joined %>%
# unnest(geo_coords) %>%
# unnest(coords_coords) %>%
# separate(geo_coords, into = c("latitude","longit"),
# sep = ";", remove = FALSE, extra = "merge") %>%
# separate(coords_coords, into = c("longitude","latit"),
# sep = ";", remove = FALSE, extra = "merge") %>%
# mutate(latitude = parse_number(latitude),
# longitude = parse_number(longitude)) %>%
select(country, lat, lng, state_country,
screen_name, status_id, location, text) %>%
filter(lat != "" | lng != "") %>%
# distinct(status_id, .keep_all = TRUE) %>%
ggplot(aes(lng, lat, color = state_country, alpha = 0.3)) +
borders() +
geom_point() +
theme_map() +
theme(legend.position = "none") +
labs(title = "Tweets around the World after Death of Charlie Watts",
color = "Country")
ggsave("pictures/worldmap_tweets_rollingstones.png",
width = 12, height = 9)
m2
Ein interaktives Diagramm können wir wiederum mit plotly erstellen.
library(plotly)
ggplotly(m2) %>% layout()Eine detailliertere und vergrößerbare Weltkarte (Paket leaflet) mit den Twitterorten aus unserem Twitter-Datensatz über den Drummer Charlie Watts und die Rolling Stones.
library(leaflet)
library(glue)
library(htmlwidgets)
library(DT)
template <- "<>{ city }</p><p>{ state_country }</p>"
tweet_map <- tweets_rollingstones_cities_joined %>%
gather(key, value,
city) %>%
mutate(key = str_to_title(str_replace_all(key, "_", " ")),
key = paste0("<b>", key, "</b>")) %>%
replace_na(list(value = "Unknown")) %>%
nest(data = c(key, value)) %>%
mutate(html = map(data,
knitr::kable,
format = "html",
escape = FALSE,
col.names = c("", ""))) %>%
leaflet() %>%
addTiles() %>%
addCircleMarkers(lat = ~ lat,
lng = ~ lng,
color = ~ state_country,
popup = ~ html,
radius = 3) %>%
addMeasure()tweet_map18.14 Zeitlicher geographischer Verlauf
Mit dem Paket gganimate sind auch Animationen möglich, die die Entwicklung eines Prozesses graphisch darstellen. In diesem Fall soll gezeigt werden, wann und wo auf der Welt Tweets nach dem Tod von Charlie Watts verfasst wurden. Nach den oben durchgeführten Korrekturen und Erweiterungen verfügen wir zumindest über fast 1000 Tweets mit ausgewiesenen Twitterorten (d.h. mit den Koordinaaten ihrer geographischen Lage), was für eine Demonstration der Animation ausreicht.
Im ersten Schritt leiten wir mit Hilfe von mutate() aus der Tabellenspalte “created at” eine Datumsspalte (date_time) ab und fügen sie unserem Datensatz hinzu. Im folgenden Chunk haben wir noch zwei weitere Datumsspalten als Varianten geschaffen, die wir bei Bedarf verwenden könnten.
tweets_rollingstones_time <- tweets_rollingstones_cities_joined %>%
mutate(date_time = lubridate::as_datetime(created_at)) %>%
mutate(dates = lubridate::as_date(created_at)) %>%
mutate(seconds = as.numeric(lubridate::as_datetime(created_at)))
tweets_rollingstones_time %>%
select(date_time, dates, seconds) %>% arrange(date_time) %>% head(3)## # A tibble: 3 x 3
## date_time dates seconds
## <dttm> <date> <dbl>
## 1 2021-08-24 16:38:55 2021-08-24 1629823135
## 2 2021-08-24 16:40:43 2021-08-24 1629823243
## 3 2021-08-24 16:42:03 2021-08-24 1629823323Nun wird die Animation vorbereitet, angezeigt und als gif-Datei gespeichert.
library(gganimate)
library(gifski)
library(ggthemes)
start = lubridate::as_datetime("2021-08-24 16:38:55")
# start = as_date("2021-08-24 16:38:55")
anim_graph <- tweets_rollingstones_time %>%
arrange(date_time) %>%
filter(!is.na(lat) & !is.na(lng)) %>%
filter(date_time >= start) %>%
add_count(city, name = "city_count") %>%
mutate(volume = city_count) %>%
ggplot(aes(lng, lat)) +
borders() +
geom_point(aes(size = volume,
color = volume)) +
theme_map() +
scale_color_gradient2(low = "blue", high = "red",
midpoint = log10(.01),
trans = "log10",
guide = "none") +
scale_size_continuous(range = c(1, 6)) + # 38
# transition_reveal(start_date) +
transition_time(date_time) +
labs(
title = "Tweets about the Rolling Stones: { round(frame_time) }") +
theme(legend.position = "none")# animation.hook="gifski"
animate(anim_graph, nframes = 300, fps = 5, device = "png")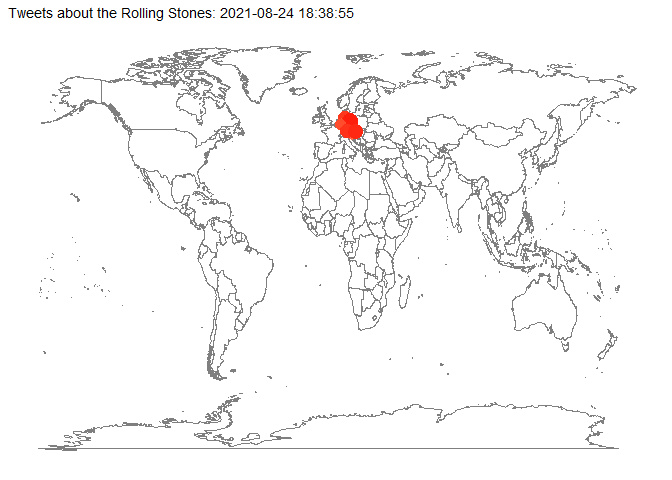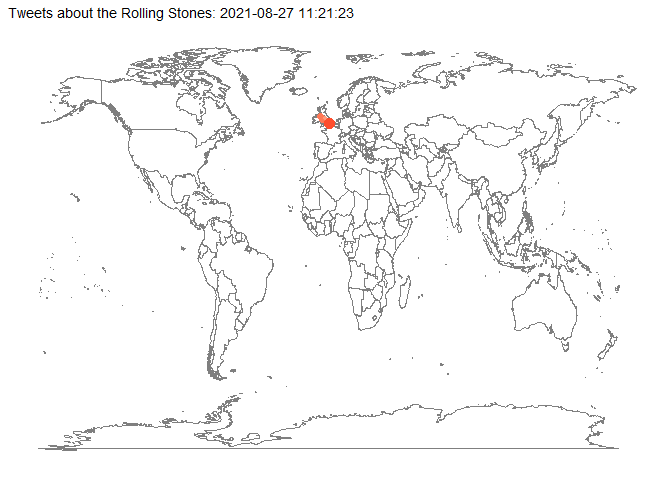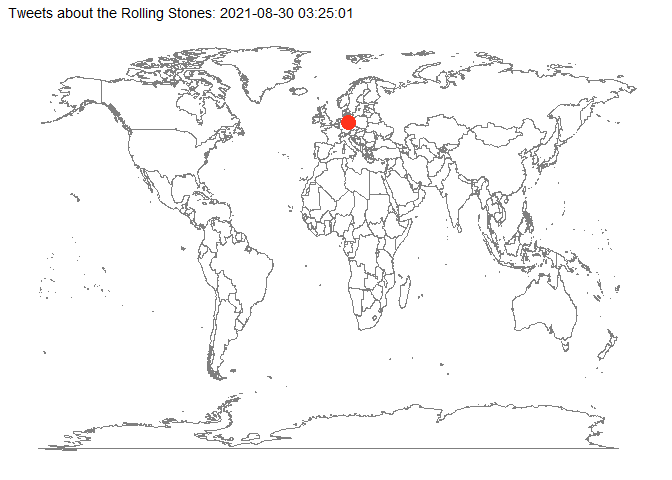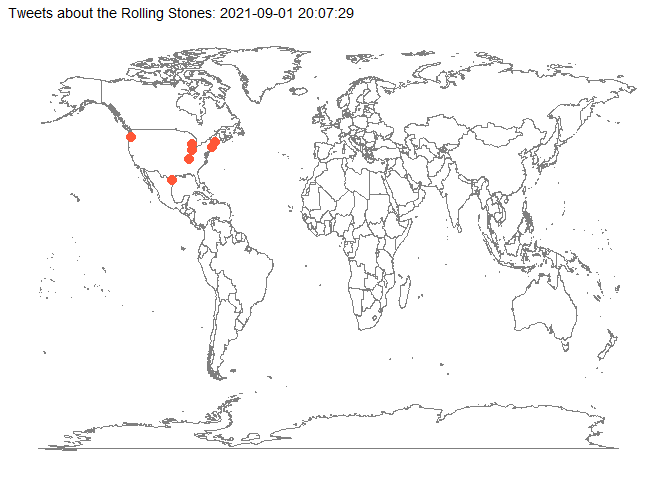
anim_save("pictures/rolling_stones_tweets_animated.png")
anim_graph
18.15 Lange Wörter
Ein spezielles Paket (ggpage), mit dem wir uns eine grobe graphische Übersicht über bestimmte quantifizierte Eigenschaften von Texten verschaffen können, und zwar über die Länge von Wörtern und ihre Textstelle. Diese graphische Darstellung kann insbesondere bei kürzeren Texten effektvoll eingesetzt werden.
library(ggpage)
tweets_rollingstones_de %>%
ggpage_build() %>%
mutate(long_word = stringr::str_length(word) > 8) %>%
ggpage_plot(aes(fill = long_word)) +
labs(title = "Longer words throughout the German Tweets") +
scale_fill_manual(values = c("grey70", "blue"),
labels = c("8 or less", "9 or more"),
name = "Word length")
18.16 Topwörter
Für die Textzerlegung und Analyse stehen uns mehrere Pakete zur Verfügung, z.B. quanteda, udpipe oder tidytext, mit denen wir schon gearbeitet haben.
Wir wählen hier das tidytext-Programm für die Textzerlegung.
Zuerst bereiten wir eine Stoppwordliste für die deutsche Sprache vor. Dann wählen wir für die Zerlegung des Textes in Wörter eine besondere Einstellung, nämlich token = "tweets", bei der hashtags (#) und URL erhalten bleiben, so dass man danach suchen kann oder sie auch abzählen oder analysieren kann. Will man nur den reinen Text analysieren, ist es notwendig, diese besonderen Zeichenfolgen aus den Tweets zu entfernen. Verwendet man die tidytext-Funktionen, kann man das Argument token = "tweets" einfach weglassen oder eine der anderen Optionen verwenden (z.B. token = "words"). Je nach Zielsetzung erhalten wir Großbuchstaben (to_lower = FALSE) oder nicht (to_lower = TRUE).
Wörter in deutschen Tweets:
library(tidytext)
stoplist_de <- as_tibble(quanteda::stopwords("german")) %>%
rename(word = value)
tw_rs_de_words <- tweets_rollingstones_de %>%
unnest_tokens(word, text, token = "tweets", to_lower = TRUE) %>%
anti_join(stoplist_de) %>%
count(word, sort = TRUE)
tw_rs_de_words %>% rmarkdown::paged_table()Wortwolke aus deutschen Tweets:
set.seed(1321)
library(wordcloud2)
w1 <- wordcloud2(tw_rs_de_words)
w1# save it in html
library(webshot)
library(htmlwidgets)
saveWidget(w1,"tmp3.html",selfcontained = F)
# save as png and pdf
webshot("tmp3.html","pictures/wcloud_tweets_rs_de.png", delay =5, vwidth = 1000, vheight=800)
webshot("tmp3.html","pictures/wcloud_tweets_rs_de.pdf", delay =5, vwidth = 800, vheight=600)Englische Tweets:
stoplist_en <- stop_words
tw_rs_en_words <- tweets_rollingstones_en %>%
unnest_tokens(word, text, token = "tweets", to_lower = TRUE) %>%
anti_join(stoplist_en) %>%
count(word, sort = TRUE)
tw_rs_en_words %>% rmarkdown::paged_table()Die am häufigsten verwendeten Schlagwörter (topfeatures) sind in beiden Sprachen annähernd gleich.
set.seed(1321)
library(wordcloud2)
w2 <- wordcloud2(tw_rs_en_words)
w2# save it in html
library(webshot)
library(htmlwidgets)
saveWidget(w2,"tmp4.html",selfcontained = F)
# save as png and pdf
webshot("tmp4.html","pictures/wcloud_tweets_rs_en.png", delay =5, vwidth = 1000, vheight=800)
webshot("tmp4.html","pictures/wcloud_tweets_rs_en.pdf", delay =5, vwidth = 800, vheight=600)18.17 Netzwerke
Welche Wörter erscheinen häufiger gemeinsam in Tweets? Welche Wortpaare (also ngrams mit n = 2 Mitgliedern) lassen sich aus den Tweets herausholen?
Arbeitet man mit tidyverse-Funktionen, kann man das Programm widyr verwenden. Im quanteda.textstats-Programm gibt es die Funktion textstat_collocations(). Auch das Programm udpipe hat Funktionen zur Ermittlung von ngrams, Kollokationen und Netzwerk-Diagramme.
library(widyr)
# remove punctuation, convert to lowercase, add id for each tweet!
tweets_rollingstones_paired_words_de <- tweets_rollingstones_de %>%
unnest_tokens(paired_words,
text,
token = "ngrams", n = 2)
tweets_rollingstones_paired_words_de %>%
count(paired_words, sort = TRUE)## # A tibble: 8,770 x 2
## paired_words n
## <chr> <int>
## 1 https t.co 464
## 2 charlie watts 203
## 3 rollingstones https 106
## 4 charliewatts rollingstones 86
## 5 die rollingstones 74
## 6 der rollingstones 73
## 7 rolling stones 57
## 8 80 jahren 46
## 9 rollingstones charliewatts 40
## 10 charliewatts https 38
## # ... with 8,760 more rowsWir verwenden wiederum die Stoppwortliste, um Funktionswörter herauszufiltern, so dass möglichst nur Kollokationen mit Inhaltswörtern übrig bleiben.
library(tidyr)
# Wörter in getrennten Tabllenspalten
tweets_rs_separated_words_de <-
tweets_rollingstones_paired_words_de %>%
separate(paired_words, c("word1", "word2"), sep = " ")
# Stoppwortliste erweitern
stoplist_de <- c(pull(stoplist_de), "https","t.co") %>%
as_tibble() %>% rename(word = value)
# Filtern
rs_tweets_filtered_de <- tweets_rs_separated_words_de %>%
filter(!word1 %in% stoplist_de$word) %>%
filter(!word2 %in% stoplist_de$word)
# new bigram counts:
rs_words_counts_de <- rs_tweets_filtered_de %>%
count(word1, word2, sort = TRUE)
head(rs_words_counts_de) %>% rmarkdown::paged_table()Aus der vorher erstellten Stoppwortliste haben wir auch die URL-Bestandteile (https, t.co) entfernt, die zwar in vielen Beiträgen vorkommen, aber keine konventionellen Wörter der deutschen Sprache darstellen.
Oben wurde schon erwähnt, dass man die URL mit tidytext- oder quanteda-Funktionen bequem entfernen kann.
Eine zwar unübersichtliche, aber ökonomische Methode ist die Verwendung eines regulären Ausdrucks (Regex), um die gesamte URL (und nicht nur die beiden oben angeführten Bestandteile) aus den Tweets zu entfernen, z.B. diese mit der Funktion gsub(), die nach einem vorgegebenen Muster (pattern) den Inhalt eines Textes oder einer Tabellenspalte durch eine (leere) Zeichenfolge ersetzt (replacement).
# Remove all url’s
gsub(pattern = "\\s?(f|ht)(tp)(s?)(://)([^\\.]*)[\\.|/](\\S*)",
replacement = "",
tweets_rollingstones$text) # unser Tweet-TextDas Netzwerk-Diagramm zeigt, welche Wörter (vor allem Inhaltswörter) in den deutschen Tweets häufiger miteinander auftreten.
library(igraph)
library(ggraph)
# plot climate change word network
# (plotting graph edges is currently broken)
rs_words_counts_de %>%
filter(n >= 5) %>% # Wie häufig muss ein Wort sein?
graph_from_data_frame() %>%
ggraph(layout = "fr") +
# geom_edge_link(aes(edge_alpha = n, edge_width = n))
geom_edge_link(aes(edge_alpha = n, edge_width = n)) +
geom_node_point(color = "darkslategray4", size = 3) +
geom_node_text(aes(label = name), vjust = 1.8, size = 3) +
labs(
title =
"Word Network: Tweets using the hashtag - RollingStones",
subtitle = "Text mining twitter data ",
x = "", y = "")
18.18 Sentiment & Emotion
Ein Paket mit zahlreichen Möglichkeiten (in verschiedenen Sprachen) für die Sentiment-Analyse ist library(syuzhet). Zusätzliche Möglichkeiten bietet auch das Paket udpipe, und zwar mit der Negationsumkehrung.
Da wir bereits Twitter-Texte in unserem Datensatz geladen haben, ist unser erster Schritt die Umwandlung der Tweets in Äußerungen. Das wird mit der Funktion get_sentences() bewerkstelligt.
library(syuzhet)
# We need to parse the text into sentences.
v_en <- get_sentences(tweets_rollingstones_en$text)Dann wird mit der Funktion get_sentiment() der Sentiment-Wert für jede einzelne Äußerung (z.B. die Summe der einzelnen Werte für die Wörter in einer Äußerung) ermittelt, und zwar auf der Grundlage von Wortlisten, in denen Wörtern emotionale Zahlenwerte zugeordnet wurden (d.h. positive oder negative Werte).
# Then we calculate a sentiment value for each sentence.
rs_sentiment <- get_sentiment(v_en)
head(rs_sentiment)## [1] 0.00 0.00 0.00 1.80 0.00 -0.25Mit der Funktion get_nrc_sentiment() können außer den polarisierten Werten (positiv vs. negativ) auch verschiedene Emtionen wie etwa Freude (joy), Trauer (sadness) und einige weitere ermittelt werden, und zwar wieder auf der Grundlage von Wortlisten, die von Versuchspersonen emotional bewertete Wörter enthalten.
rs_nrc_sentiment <- get_nrc_sentiment(v_en)
joy_items <- which(rs_nrc_sentiment$joy > 0)
head(v_en[joy_items], 4)## [1] "We ended up no more than 20ft off the stage that night and right by the catwalk it was brilliant."
## [2] "I know this is late to the table but in honour of Charlie Watts @RShrubb I thought I share a great @harleydavidson tribute to @RollingStones #CharlieWatts RIP https://t.co/qeyqaMB8Fc"
## [3] "She and I queued and then ran when gates open straight to the mosh and sat there for 10hrs waiting in the sun on the hottest day of that year!!!"
## [4] "<U+0001F538>#Robonzo <U+0001F941> \n<U+0001F539>#Song: 'On Top Of The World' \n[#alternative, #psychadelic~#Rock\n#drummer #guitarist #musician\n#RollingStones #Spotify #YouTube \n#Apple~#Music #Amazon #Pandora]\n<U+0001F538>#Website:\n<U+23E9> https://t.co/zBW0D0wk6U\n<U+0001F538>#Video via: (@RobonzoDrummer)\n<U+23E9> https://t.co/SKRzZWNOrz https://t.co/ECWAc4tysM"Hier ist ein Ausschnitt aus solch einer Tabelle, die wir nach der Ermittlung der emotionalen Werte von Wörtern erhalten:
rs_nrc_sentiment[1:10, 1:10] %>% rmarkdown::paged_table()Die emotionale Valenz (d.h. wie positiv oder negativ die Bedeutung eines Wortes bewertet wird):
valence_rs <- (rs_nrc_sentiment[, 9]*-1) + rs_nrc_sentiment[, 10]
head(valence_rs)## [1] 0 0 0 1 0 -1In den englischen Tweets wurden Wörter gefunden, die häufig Emotionen wie Freude, Zuversicht, Erwartung, Trauer ausdrücken. Das Ergebnis können wir wenigen Zeilen graphisch darstellen.
barplot(
sort(colSums(prop.table(rs_nrc_sentiment[, 1:8]))),
horiz = TRUE, cex.names = 0.7, las = 1, col = 9:2,
main = "Emotions in Tweets", xlab="Percentage"
)
Hier ist eine ästhetisch etwas ansprechendere, aber auch erweiterbare graphische Darstellung mit ggplot():
library(scales)
rs_nrc_sentiment[,1:8] %>%
summarise(across(everything(), ~ mean(.))) %>%
pivot_longer(anger:trust,
names_to = "emotion",
values_to = "pct") %>%
mutate(emotion = fct_reorder(emotion, pct)) %>%
ggplot(aes(pct, emotion, fill = emotion)) +
geom_col() +
theme(legend.position = "none") +
scale_x_continuous(labels = percent) +
labs(x = "", y = "",
title = "Emotion in English Tweets after Death of Charlie Watts")
ggsave("pictures/rs_emotions_en.png") Zum Vergleich die deutschen Tweets:
Zunächst wiederum die Umwandlung in Äußerungen, gefolgt von der Ermittlung der emtionalen Werte von Wörtern.
v_de <- get_sentences(tweets_rollingstones_de$text)
rs_nrc_sentiment_de <- get_nrc_sentiment(v_de, language = "german")
joy_items_de <- which(rs_nrc_sentiment_de$joy > 0)
head(v_de[joy_items_de], 4)## [1] "Wir gedenken dem @RollingStones Drummer mit einem stündigen #PopRoutes Special abem 9ni uf @srf3 \n\nhttps://t.co/yXUtyb12y4"
## [2] "Synagoge von Vilnius gefunden."
## [3] "Und ganz ehrlich… ich freue mich auf jeden Ton, der noch von ihnen kommt."
## [4] "Niemand ist unsterblich."Die graphische Darstellung der emotionalen Werte in deutschen Tweets:
rs_nrc_sentiment_de[,1:8] %>%
summarise(across(everything(), ~ mean(.))) %>%
pivot_longer(anger:trust,
names_to = "emotion",
values_to = "pct") %>%
mutate(emotion = fct_reorder(emotion, pct)) %>%
ggplot(aes(pct, emotion, fill = emotion)) +
geom_col() +
theme(legend.position = "none") +
scale_x_continuous(labels = percent) +
labs(x = "", y = "",
title = "Emotion in German Tweets after Death of Charlie Watts")
ggsave("pictures/rs_emotions_de.png") Was für ein Unterschied! Woran das wohl liegen mag? Das müsste man sich auf jeden Fall mal genauer anschauen.
18.19 Sentiment (Animation)
Auch hier können wir es mit einer Animation des Sentiments in den englischen Tweets versuchen. Da die Berechnung länger dauern könnte, wählen wir nur etwa 500 Tweets zur graphischen Darstellung des Sentiments aus.
library(ggpage)
library(purrr)
library(gganimate)
library(tidytext)
library(zoo)
# Beschränkung auf die Tweets 1000 bis 1500
prebuild <- tweets_rollingstones_en$text[1000:1500] %>%
ggpage_build() %>%
left_join(get_sentiments("afinn"), by = "word")
midbuild <- map_df(.x = 0:50 * 10 + 1, ~ prebuild %>%
mutate(score =
ifelse(is.na(value), 0, value),
score_smooth = zoo::rollmean(score, .x, 0),
score_smooth = score_smooth /
max(score_smooth),
rolls = .x))
anim_pages <- midbuild %>%
ggpage_plot(aes(fill = score_smooth)) +
scale_fill_gradient2(low = "red", high = "blue", mid = "grey",
midpoint = 0) +
guides(fill = "none") +
labs(
title = "Smoothed sentiment of Rolling Stones Tweets, rolling average of {round(frame_time)}") +
transition_time(rolls)anim_pages